결제 시스템에서의 트랜잭션 설계하기 (1부)
1부. 트랜잭션 설계와 멱등성 보장
시리즈 구성
이 글은 결제 시스템을 실제로 구현하면서, 설계가 왜 그렇게 될 수밖에 없었는지를 설명하며 연재해 나가려 합니다. 결제 시스템은 보통 코드만 보면 단순해 보입니다. Payment 상태 바꾸고, PG(PSP) 승인 API 호출하고, 결과 저장하면 끝처럼 보입니다. 그런데 운영 환경에서 진짜 문제는 성공/실패의 결과가 아니라, 그 결과가 어떤 순서로, 어떤 보장 위에서, 어떤 예외 상황에서도 복구 가능하게 남는가에 있습니다.
- 사용자가 결제 버튼을 두 번 클릭하면?
- 네트워크 타임아웃으로 클라이언트가 재시도하면?
- PG는 승인 성공인데 우리 DB는 롤백되면?
- 웹훅이 2번 오거나, 늦게 오거나, 아예 누락되면?
- 순간적으로 트래픽이 몰려 DB 커넥션 풀이 고갈되면?
이런 상황에서 트랜잭션을 걸었다는 말만으로는 아무것도 설명되지 않습니다.
그래서 이 시리즈는 코드 → DB 내부 → 동시성 → 정합성 모델까지 어떤 고민과 학습을 통해 설계했는가를 정리하려 합니다.
1부. 트랜잭션 설계와 멱등성 보장
- 결제 승인(confirm)에서 트랜잭션을 “왜 짧게” 가져가야 하는가
- DB는 트랜잭션을 어떻게 보장하는가 (Undo/Redo/WAL/fsync/MVCC)
- InnoDB 락은 왜 인덱스를 잠그고, next-key/gap 락이 어떻게 생기는가
- Spring 전파(REQUIRES_NEW)로 짧은 트랜잭션을 쪼갤 때의 정합성 모델
- 멱등성 로그(PaymentCommandLog)로 “중복 결제”를 구조적으로 차단하는 방법
2부. Webhook 처리와 조정(Reconciliation)
- 웹훅 서명 검증(위조 방지)과 이벤트 중복 처리 (eventId UNIQUE)
- “PG는 성공인데 우리 DB는 실패” 같은 불일치를 어떻게 발견하는가
- 재처리 설계: 어떤 상태를 기준으로, 어떤 순서로, 어디까지 자동화할 것인가
3부. 성능 최적화: N+1 쿼리와 인덱싱 전략
- 결제 확정 시 원장/지갑 엔트리 조회가 N+1로 터지는 패턴
- 인덱스 설계가 곧 락 범위 설계가 되는 이유 (결제 도메인 관점)
- p95/p99 지표로 보는 빠른데 안전한 구조 만들기
4부. 결제 시스템 보안: 서명 검증과 방어 전략
- 웹훅 위변조 방지(서명 검증), 리플레이 공격 방지
- 결제 금액 변조, orderId 변조, 중간자 공격을 어떻게 막는가
- 결제 시스템에서 신뢰의 경계를 어디에 둘 것인가
PS. 이번 설계를 통해 그동안 미뤄왔던 MySQL 책을 조금이라도 읽어나가게 되어 기쁩니다..
왜 1부가 ‘트랜잭션’부터 시작하나
결제 시스템에서 트랜잭션은 단순한 DB에 저장하는 기능이 아닌, 정합성의 최후 방어선이라고 생각했습니다.
여기서 말하는 정합성은 단순히 row 하나가 저장되었는가가 아니라, 다음이 동시에 만족되는 상태를 의미합니다.
- 결제 상태가 올바르게 전이되었고 (INITIATED → AUTHORIZED → CONFIRMED/FAILED)
- 멱등성 로그가 동일 요청을 단 한 번만 처리하도록 막았고
- 원장(ledger)이 반드시 결제 결과와 1:1로 대응하며
- 장애가 나도 “어떤 요청이 어디까지 처리됐는지” 추적 가능하고
- 재시도/웹훅/지연 도착 같은 비정상 흐름에서도 복구 가능한 구조
트랜잭션 범위를 너무 넓게 잡게 되면, 다음 정합성이 깨지기 쉽다고 생각했습니다. 직관적으로는 ‘한 번의 결제 승인 작업’이니까 아래처럼 하나로 묶는다고 합시다.
1
2
3
4
5
6
7
8
@Transactional
public PaymentResult confirm(...) {
Payment p = paymentRepository.lockByOrderId(orderId);
ConfirmResult r = paymentProvider.confirm(...); // 외부 네트워크
p.confirmed();
ledger.append(...);
return PaymentResult.from(r);
}
그런데 결제에서는 외부 I/O가 반드시 끼어들고, 외부 I/O는 우리가 통제할 수 없습니다. 즉, 트랜잭션이 길어지면 다음 상황이 구조적으로 발생합니다.
- DB 커넥션 점유 시간 증가 → 커넥션 풀 고갈 → 전체 요청 대기
- 락 유지 시간 증가 → 동시성 급락 → 응답 지연, 데드락 가능성 상승
- PG 승인 성공 + DB 롤백 같은 최악의 불일치가 실제로 만들어짐
그래서 저는 결제 confirm을 설계할 때, 단순히 @Transactional을 붙이는 게 아닌, DB가 보장해 줄 수 있는 범위와 DB가 절대 보장 못하는 범위(외부 I/O)를 분리하는 것을 1순위로 잡았습니다.
따라서 제가 선정한 이 시리즈의 핵심 철학은 한 문장으로 요약하면 이렇습니다.
- 트랜잭션은 짧게, 커밋은 확실하게.
- 외부 I/O는 트랜잭션 밖으로.
- 깨질 수 있는 원자성은 ‘운영 가능한 최종 일관성 모델’로 메운다.
따라서 이 글의 전제는, 원자성보다 복구 가능성을 선택하는 것입니다.
이 말은 대충 설계한다는 뜻이 아닌, 결제 시스템에서는 모든 상황에서 완벽한 원자성(ACID의 A)을 끝까지 지키는 것이 실제로는 더 큰 장애를 부를 수 있다고 생각했습니다.
외부 PG는 분산 트랜잭션(2PC)에 참여하지 않습니다. 따라서 네트워크는 느려질 수 있고, 끊길 수 있고, 타임아웃이 날 수 있습니다. 그럼에도 결제 시스템은 죽지 않고 버텨야 합니다.
그래서 1부에서는 왜 분리를 선택했는지를 설명하기 위해 DB 내부의 트랜잭션 보장 메커니즘과 InnoDB 락/격리수준을 결제 맥락에 맞춰 연결해 작성해나가려 합니다.
다음 파트에서는 가장 먼저, 이 질문부터 시작하려 합니다.
DB는
COMMIT을 했을 때, 정확히 무엇을 어디에 어떻게 남기길래 장애가 나도 데이터가 살아남는 걸까요?
결제 시스템에서 트랜잭션은 시작이 아니라 마지막 방어선이다
트랜잭션 = 안전이라는 착각
결제 시스템을 설계하며 트랜잭션에 대해 고민해보기 전까지만 해도, 트랜잭션을 그저 이렇게 이해했습니다.
- BEGIN
- 여러 쿼리 실행
- COMMIT 또는 ROLLBACK
그래서 초반에는 결제 승인 로직을 자연스럽게 이런 식으로 생각했습니다.
1
2
3
4
5
6
7
@Transactional
public void confirmPayment(...) {
Payment payment = paymentRepository.lockByOrderId(orderId);
pgClient.confirm(paymentKey); // 외부 API
payment.confirmed();
ledger.append(...);
}
겉보기에는 완벽해 보이지만, 이 코드에는 DB 트랜잭션이 절대 책임질 수 없는 영역이 섞여 있습니다.
바로 pgClient.confirm(...) 같은 외부 I/O입니다.
DB 트랜잭션은 오직 DB 내부 상태만 되돌릴 수 있습니다. 네트워크 요청, 외부 서버의 처리 결과, 카드사의 승인 상태는 ROLLBACK 대상이 아니라는 사실을 망각했던 겁니다.
즉, 다음과 같은 상황이 언제든지 발생 가능합니다.
- PG 서버는 결제를 승인 완료한 상태에서
- 우리 서버는 승인 직후 DB 커밋 전에 장애가 나게 되어
- DB에는 결제가 없는 상태에서
- 사용자는 “결제 안 됐어요?”라고 문의하는 상황
이건 버그가 아니라 설계 결과입니다. 즉, 원인은 트랜잭션을 크게 잡았기 때문에 생긴 문제라고 판단했습니다.
DB 트랜잭션이 실제로 보장하는 것
여기서 잠깐 멈추고, DB 트랜잭션이 정확히 무엇을 보장하는지 짚고 가봅시다.
DB의 트랜잭션은 ACID를 보장한다고 말합니다.
- Atomicity: 전부 성공하거나 전부 실패
- Consistency: 규칙을 깨지 않음
- Isolation: 동시에 실행돼도 서로 간섭 안 함
- Durability: COMMIT 이후에는 장애가 나도 남음
하지만 이 네 가지는 모두 DB 내부 세계에 한정된 이야기입니다.
DB는 이런 질문에는 답할 수 없습니다.
- PG가 실제로 승인했는가?
- 카드사가 돈을 정산했는가?
- 네트워크 중간에서 응답이 유실됐는가?
그래서 결제 시스템에서 진짜 중요한 질문은 다음이라고 생각했습니다.
“DB 트랜잭션이 닿지 않는 영역을 어떻게 설계로 보완할 것인가?”
그래서 결제 설계를 분리에서 시작하기로 했습니다.
이에 따라, 결제 시스템의 기본 구조를 다음과 같이 나눴습니다.
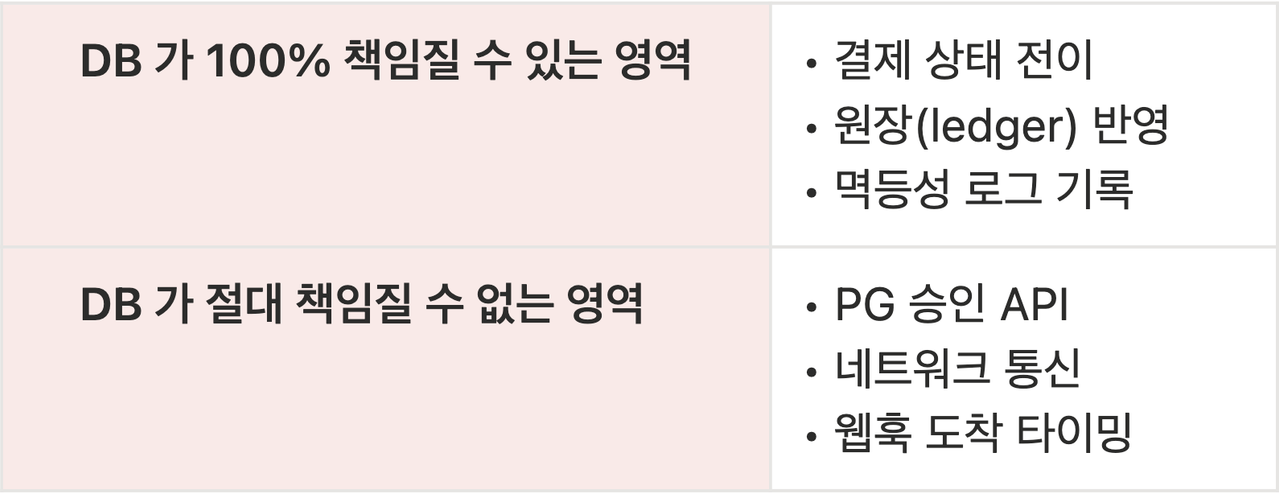
이 둘을 한 트랜잭션에 넣는 순간, 우리는 원자성을 얻을 순 있을지언정 복구 불가능한 상태를 초래할 수 있다 판단했습니다.
따라서 실제 결제 설계에서는 이런 방향을 선택하기로 합니다.
- DB 트랜잭션은 짧게
- 외부 I/O는 트랜잭션 밖으로
- 깨질 수 있는 원자성은 멱등성 + 재처리 + 웹훅 조정으로 해결
이게 바로 뒤에서 계속 등장할 최종 일관성(Eventual Consistency) 모델입니다.
짧은 트랜잭션이 왜 중요한가
트랜잭션이 길어질수록 발생하는 문제는 단순 성능 저하가 아닙니다.
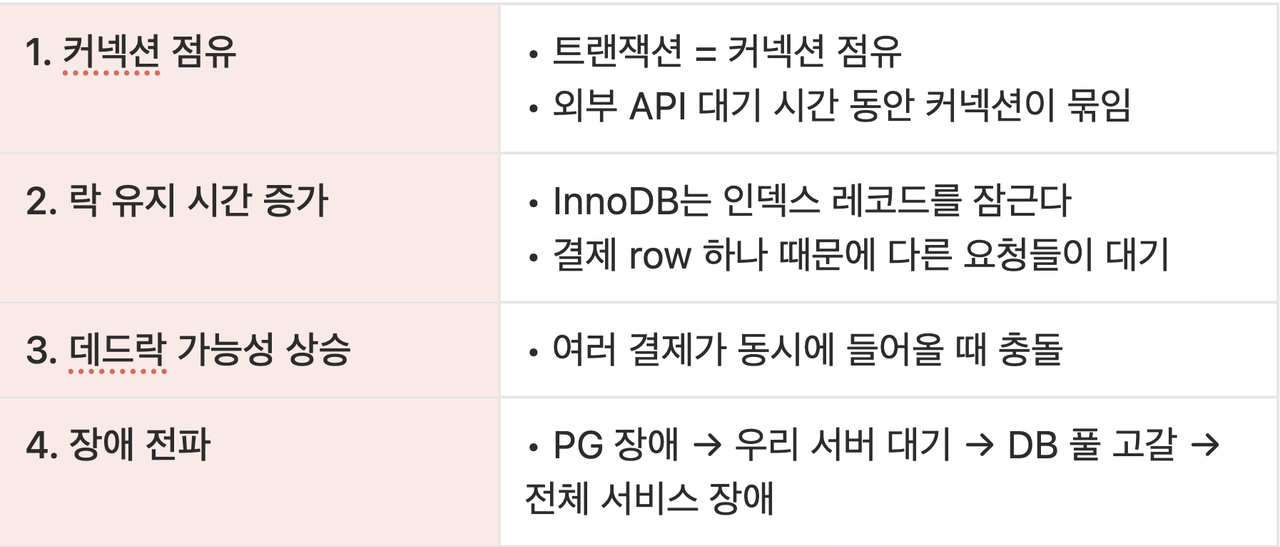
그래서 결제 시스템에서 트랜잭션은 빨리 시작해서, 빨리 끝내는 것이 핵심입니다.
이 시점에서 자연스럽게 다음과 같은 의문이 듭니다.
- DB는 COMMIT을 어떻게 진짜로 보장하는가?
- 장애가 나도 남는다는 건 구체적으로 무슨 뜻인가?
- Undo / Redo / WAL / fsync / MVCC는 각각 무슨 역할을 하는가?
- 왜 InnoDB는 레코드를 잠그는 게 아니라 인덱스를 잠그는가?
이 질문에 답하지 않으면, Spring의 @Transactional, REQUIRES_NEW 같은 옵션은 주문처럼 외우는 설정값으로 남는다.
그래서 이제 DB 내부에서 실제로 무슨 일이 벌어지는지를 하나씩 내려가려 합니다. 따라서 다음 내용들을 작성하고자 합니다.
- Undo Log
- Redo Log
- WAL(Write-Ahead Logging)
- fsync
- 그리고 MVCC가 왜 필요한지
DB는 COMMIT을 했을 때, 정확히 무엇을 어디에 남기는가
COMMIT 했으면 안전한 거 아닌가요?
이 질문은 절반만 맞습니다. 무엇으로부터 안전한가?를 묻지 않았기 때문입니다. DB가 보장하는 안전함은 서버 프로세스가 죽거나, OS가 죽거나, 전원이 나가도 데이터를 복구할 수 있다는 의미입니다.
DB는 전원 차단, 커널 패닉, OOM, 디스크 장애, 강제 재시작 등의 상황으로 인해 언제든 죽을 수 있습니다. 따라서 InnoDB는 메모리에 있는 데이터는 믿지 않는다는 가정을 합니다. UPDATE 쿼리가 끝났으니 DB에 저장됐다 생각하기 쉽지만, 실제로 그렇지 않습니다. 실제로는 데이터는 메모리(Buffer Pool) 에 먼저 반영하고, 디스크 반영은 나중에 진행합니다. 그럼 서버가 죽으면 다 날아가는 거 아닌가? 라는 의문이 생길 수 있습니다.
이걸 가능하게 만드는 핵심 메커니즘이 바로 Undo Log, Redo Log, WAL, fsync, MVCC입니다.
1. 트랜잭션이 시작되면, InnoDB는 가장 먼저 Undo를 준비한다
결제 승인 로직에서 이런 쿼리가 있다고 가정해봅시다.
1
2
3
UPDATE payment
SET status = 'CONFIRMED'
WHERE order_id = 'ORD-1001';
이 순간 InnoDB는 바로 데이터를 덮어쓰지 않습니다, 대신 가장 먼저 하는 일이 있는데요,
되돌릴 수 있는 정보부터 기록한다.
이게 바로 Undo Log 입니다. Undo Log에는 이런 정보가 들어갑니다.
- 변경 전 값 (status = AUTHORIZED)
- 해당 변경을 수행한 트랜잭션 ID
- 롤백 시 어떻게 복구할지에 대한 정보
즉, 이 레코드는 이전 값이 뭐였는지에 대한 정보가 저장됩니다. 또, Undo Log는 이렇게 사용됩니다.
- 트랜잭션 실패 → ROLLBACK
- 서버 장애 발생 → 미완료 트랜잭션 취소
- MVCC에서 과거 버전 제공
다음과 같은 상황을 가정해봅시다.
1
2
3
4
BEGIN
UPDATE balance = balance - 100
-- 여기서 에러
ROLLBACK
Undo가 없다면 이미 바뀐 값을 복구할 수 없고 트랜잭션은 의미를 잃습니다.
MVCC: 락 없이 읽는 마법
읽기 중에 누군가 쓰는 상황에서 Undo의 진짜 쓰임새가 나옵니다. 전통적인 방식에서는 읽을 때 락, 쓰기 중엔 대기학에 성능이 안나올 수 있습니다. 이를 위해 InnoDB는 MVCC을 선택합니다. 이는 과거 버전을 보여주는 방식으로,
- 트랜잭션 A가 UPDATE 중
- 트랜잭션 B가 SELECT
하는 상황에서 B는 Undo Log에 있는 이전 버전을 읽도록 하는 것입니다. 따라서 SELECT * FROM payment; 구문에서 누군가 UPDATE 중이어도 대기 없이 즉시 응답이 가능해집니다.
즉, Undo Log 없이는 원자성(Atomicity)도, 격리성(Isolation)도 불가능합니다.
2. 실제 데이터는 메모리(Buffer Pool)에서 먼저 바뀐다
Undo Log를 남겼다면 이제 데이터를 바꿀 수 있습니다. 하지만 여기서 중요한 포인트가 있습니다.
바로 InnoDB는 디스크에 바로 쓰지 않는다는 점인데요.
변경된 레코드는 먼저 Buffer Pool 안의 페이지에서 수정됩니다.
이 상태를 보통 Dirty Page (메모리에는 반영됐지만 디스크에는 아직인 상태) 라 부릅니다.
아직 디스크에 안 써졌으면 위험한 거 아닌가 싶은데요, 이를 위해서 다음 단계가 등장합니다.
3. Redo Log와 WAL: 먼저 기록하고, 나중에 반영
InnoDB는 데이터 페이지보다 먼저 Redo Log에 변경 내용을 기록합니다. 이 원칙을 WAL (Write-Ahead Logging) 이라고 부릅니다. 해당 순서는 다음과 같습니다.
- Undo Log 기록
- Buffer Pool 데이터 변경
- Redo Log에 변경 사실 기록
- COMMIT
즉, WAL의 핵심 원칙은 데이터보다 로그를 먼저 쓴다는 것입니다. 변경 내용을 로그에 기록하고, 로그가 디스크에 안전하게 저장되면 그 다음에 실제 데이터가 변경되도록 합니다. 이 순서가 깨지면 트랜잭션은 의미가 없어집니다.
따라서 Redo Log에는 물리적인 변경 정보 (after-image 중심)나 어떤 페이지의 어떤 위치가 이렇게 바뀌었는지와 같은 내용이 들어갑니다. 즉, Redo Log의 핵심 목적은 커밋된 트랜잭션을 다시 재현하며, 서버가 죽어도 다시 켜면 COMMIT된 변경을 재적용할 수 있게 하는 것입니다.
1
2
// Redo Log 입력된 정보 예시
ex) 페이지 X의 offset Y를 값 A → B로 변경
다음과 같은 상황을 가정해봅시다.
1
UPDATE payment SET status='CONFIRMED'
다음 COMMIT 이 메모리에 반영된 상태에서 디스크에는 아직 안 썼는데 갑자기 서버 다운됐습니다. 이때 Redo Log를 읽게 되면 이건 커밋된 거래였음을 인지하고 다시 적용할 수 있습니다.
즉, 결제 승인 도중 서버가 전원 OFF 되어도:
- 디스크의
payment테이블은 아직CONFIRMED가 아닐 수 있음 - 하지만 Redo Log에
CONFIRMED로 바꿔라는 기록이 있음 - 재시작 시
Redo Log를 읽어서 다시 적용
이게 Durability(지속성) 입니다.
Redo vs Undo 정리
| 구분 | Redo | Undo |
|---|---|---|
| 목적 | 커밋 복구 | 롤백 |
| 시점 | COMMIT 후 | COMMIT 전 |
| 장애 시 | 다시 적용 | 무시 |
| 읽기 | 복구 시 | MVCC |
4. fsync: 로그를 디스크에 진짜로 쓰는 순간
여기서 한 단계 더 깊이 들어가야 합니다. Redo Log를 썼다고 해서 바로 안전한 건 아닙니다.
OS의 페이지 캐시에만 있으면 전원 OFF 시 같이 날아가기 때문입니다.
운영체제는 write() 성공 이라는 거짓말을 합니다. 사실 이는 커널 버퍼에 썼다는 의미지, 디스크 아니기 때문입니다. fsync()는 지금 당장, 디스크 플래터에 써라는 의미를 지닙니다.
그래서 COMMIT 시점에는 보통 다음과 같은 작업이 수행됩니다.
- Redo Log buffer → OS buffer
fsync()호출- OS buffer → 디스크 플래터 / SSD
fsync가 끝났다는 말은 곧 이 COMMIT은 전원 코드 뽑아도 남는다는 뜻입니다. 그래서 결제 시스템에서 COMMIT이 느린 이유의 상당 부분은 fsync 때문입니다. 디스크 성능, 동시 커밋 수, 그룹 커밋 설정 과 같은 모든 게 결제 TPS에 직접적인 영향을 줍니다.
즉, 한마디로 요약하자면 InnoDB는 커밋 시 Redo Log에 fsync 수행하기에 커밋이 느릴 수 있지만, 전원 꺼져도 살아남습니다.
[참고] innodb_flush_log_at_trx_commit
이 설정은 트레이드오프 핵심으로 각 설정 값은 다음을 의미합니다.
값 의미 0 1초에 한 번 fsync 1 매 COMMIT마다 fsync (기본) 2 로그는 쓰되 fsync는 1초마다
5. 그럼 Undo Log는 언제 지워질까?
Undo Log는 바로 지워지지 않습니다. 이유는 크게 두 가지인데요.

예를 들어, 다음과 같은 상황을 가정해봅시다.
- 트랜잭션 A: 결제 상태
CONFIRMED로 변경 (아직 COMMIT 안 됨) - 트랜잭션 B: 결제 상태 조회
이때 B는 AUTHORIZED 상태를 봐야 합니다. 이때 사용하는 게 Undo Log에 남아 있는 이전 버전입니다.
그래서 Undo Log는 모든 관련 트랜잭션이 끝난 뒤에야 정리됩니다.
6. 이 모든 게 결제 설계에서 왜 중요한가
여기까지 내용을 결제 시스템에 다시 대입해봅시다.
- DB는
COMMIT된 상태만 책임진다 - 외부 PG 승인 여부는
Redo Log에 남지 않는다 - 네트워크 타임아웃은
Undo/Redo로 복구되지 않는다
그래서 이런 설계가 나오는 것입니다.
- 승인 의도는 DB에 먼저 기록 (
AUTHORIZED/IN_PROGRESS) - 외부 PG 호출은 트랜잭션 밖
- 결과 반영은 다시 짧은 트랜잭션
이 구조는 DB가 잘하는 것(DB 내부 정합성) 과 DB가 못하는 것(외부 세계) 을 명확히 분리한 결과입니다.
제 설계에 있어,
1
2
3
A-1 멱등키 선점 → COMMIT
A-2 결제 예약 → COMMIT
C 결과 반영 → COMMIT
각 단계는 Redo Log fsync 를 통해 서버가 죽어도 커밋된 상태는 살아남게 됩니다.
락은 왜 생기고, InnoDB는 왜 레코드가 아니라 인덱스를 잠그는가
여기까지 살펴보고나면, 다음과 같은 질문이 들 수 있습니다.
MVCC도 있고 Undo Log도 있는데, 왜 굳이 락까지 걸어야 하지?
실제로 읽기(Read) 는 대부분 락 없이 처리됩니다. 그럼에도 쓰기(Write) 에 락이 필요한 이유는 딱 하나인데요.
같은 데이터를 동시에 바꾸는 순간, 어떤 변경이 먼저였는지 결정해야 하기 때문
따라서 이를 이해하기 위해, 락이 왜 생겼는지, InnoDB는 왜 레코드가 아니라 인덱스 를 잠그는지 Gap / Next-Key Lock이 왜 존재하는지를 결제 시스템 시나리오로 풀어 설명해보고자 합니다.
1. 락의 본질: “동시 변경 충돌”을 막기 위한 최소 장치
다음 상황을 생각해봅시다.
1
2
3
4
5
- 주문 ORD-1001
- 상태: AUTHORIZED
- 동시에 두 요청이 들어온다
- 요청 A: 결제 승인(CONFIRM)
- 요청 B: 결제 취소(CANCEL)
둘다 이렇게 동작할 것입니다.
1
2
3
UPDATE payment
SET status = 'CONFIRMED'
WHERE order_id = 'ORD-1001';
1
2
3
UPDATE payment
SET status = 'CANCELED'
WHERE order_id = 'ORD-1001';
이 상황에서, 만약 락이 없다면?
- A가 읽음 →
AUTHORIZED - B가 읽음 →
AUTHORIZED - A가 씀 →
CONFIRMED - B가 씀 →
CANCELED결과는 마지막으로 커밋한 쪽이겠지만, 비즈니스적으로는 치명적 오류가 될 수 있습니다. 따라서 DB는 누군가 이 데이터를 바꾸는 동안 다른 사람은 기다리도록 보장합니다.
더 직관적인 예시를 살펴봅시다.
1
2
3
4
초기 잔액: 10,000원
TX-A: -3,000
TX-B: -5,000
인 상황에서,
- A 읽음 → 10,000
- B 읽음 → 10,000
- A 저장 → 7,000
- B 저장 → 5,000 ❌
실제로는 2,000원이 남아야 하지만, 5000원으로 저장되는 상황이 발생합니다. 그래서 DB는 말합니다. 한 명씩 해 그리고 이게 락의 시작입니다.
2. InnoDB의 핵심 특징: 레코드를 잠그지 않는다
여기서 중요한 오해 하나부터 바로잡아봅시다.
❌ InnoDB는 레코드를 잠근다
✅ InnoDB는 인덱스 레코드를 잠근다
이 차이는 매우 큰데요. 이때 왜 왜 레코드가 아니라 인덱스일까요? InnoDB에서 모든 접근은 인덱스 탐색으로 이루어집니다.
- PK 조건 → 클러스터 인덱스
- 유니크 키 → 유니크 인덱스
- 일반 조건 → 보조 인덱스
- 인덱스 없음 → 내부적으로 생성된 클러스터 인덱스
즉, DB가 어떤 레코드를 찾았는지 는 어떤 인덱스를 사용했는지 로 결정된다는 뜻입니다. 따라서 락도 인덱스 기준으로 걸립니다.
다음 구문을 살펴봅시다.
1
2
3
UPDATE payment
SET status = 'CONFIRMED'
WHERE order_id = 'ORD-1';
DB 내부는 다음과 같이 동작합니다.
order_id 인덱스를 탐색하고, 해당 인덱스 엔트리 찾습니다. 그 후, 그 인덱스를 잠금 후 레코드를 변경합니다. 그래서 조건에 사용된 인덱스가 락 범위를 결정하게 됩니다. 이때 만약 인덱스가 없다면
1
2
3
UPDATE payment
SET status = 'CONFIRMED'
WHERE user_id = 123;
다음 상황에서 테이블 풀 스캔한 후, 모든 레코드를 검사하고 모든 인덱스 엔트리에 락을 거는 사실상 테이블 락과 동일한 효과를 지니게 됩니다. 그래서 결제 시스템에서 인덱스 설계는 성능이 아니라 락 범위 설계가 됩니다.
3. Record Lock: 이 인덱스 엔트리 하나만 잠근다
가장 단순한 락부터 봅시다.
1
2
3
SELECT * FROM payment
WHERE order_id = 'ORD-1001'
FOR UPDATE;
order_id가 PK 또는 유니크 인덱스- 딱 하나의 인덱스 엔트리만 매칭
이때, InnoDB는 해당 인덱스 엔트리 하나와 그에 대응하는 레코드에만 락을 겁니다. 이게 이게 Record Lock입니다. 즉, 하나의 인덱스 엔트리에 대한 락을 의미합니다.
해당 내용이 결제 시스템에서 어떤 의미를 지니는지 살펴보면
lockByOrderId(orderId)- 이 주문은 지금 내가 책임진다
- 다른 트랜잭션은 이 주문을 건드릴 수 없는 상태
이는 락 범위 최소 + 동시성 최대가 되게 하기 위함입니다. 즉, order_id가 UNIQUE 인덱스인 상황으로 정확히 1건만 락이 되는, 결제 시스템에서 가장 이상적인 락의 형태를 지니게 됩니다.
4. Gap Lock: 존재하지 않는 공간을 잠근다?
다음과 같은 상황을 살펴봅시다.
1
2
order_id 인덱스 값:
ORD-1, ORD-5, ORD-9
1
2
3
SELECT * FROM payment
WHERE order_id BETWEEN 'ORD-3' AND 'ORD-8'
FOR UPDATE;
이때 락 대상은
- ORD-5 (레코드 락)
- ORD-1 ~ ORD-5 사이 (Gap)
- ORD-5 ~ ORD-9 사이 (Gap)
으로 이 범위에 새로운 INSERT 을 차단할 수 있습니다.
이쯤 되면 이런 의문이 생기는데요.
존재하는 레코드만 잠그면 되는 거 아냐?
하지만 DB에는 또 하나의 위험이 있습니다.
Phantom Read (유령 읽기)
1
2
3
SELECT * FROM payment
WHERE amount BETWEEN 10000 AND 20000
FOR UPDATE;
해당 쿼리를 실행하는 동안 다른 트랜잭션이 새로운 결제 레코드를 INSERT하면 어떻게 될까요? 처음 조회 결과와 나중 조회 결과가 달라질 것입니다.
이를 막기 위해 InnoDB는 이미 있는 레코드뿐 아니라 그 사이 공간도 잠가버리는 방식을 택합니다. 이게 바로 Gap Lock입니다.
- 레코드와 레코드 사이의 간격
- 아직 존재하지 않는 값의 범위
5. Next-Key Lock: Record + Gap의 합체
실제 InnoDB에서 가장 흔히 걸리는 락은 Next-Key Lock입니다.
Record Lock + Gap Lock
이는 찾은 레코드는 잠그고 그 앞뒤 “범위”도 함께 잠근다는 의미로, REPEATABLE READ, 범위 조건, 유니크 인덱스가 아닌 경우 에 발생합니다.
1
2
3
SELECT * FROM payment
WHERE created_at >= '2025-01-01'
FOR UPDATE;
따라서 이 쿼리는 기존 레코드는 물론 미래에 들어올 레코드까지 전부 차단하는 겁니다.
다시 말하면, 현재 레코드는 못 바꾸게 하고 그 앞뒤로 새로운 레코드도 못 들어오게 하는 상태인데요. 왜 이렇게까지 하냐 하면, MySQL 의 기본 격리 수준이 REPEATABLE READ 이기 때문입니다. 같은 트랜잭션 안에서는 같은 SELECT결과를 보장해야 합니다. 이 보장을 깨지 않기 위해 InnoDB는 꽤 공격적으로 락을 겁니다.
6. 결제 시스템에서 Next-Key Lock이 위험해지는 순간
이제 이걸 결제 코드에 대입해봅시다.
1
2
3
UPDATE payment
SET status = 'CONFIRMED'
WHERE user_id = 10;
user_id에 인덱스가 있고 한 유저의 결제 내역이 여러 건 존재하는 상태입니다
이때, 해당 쿼리가 의미하는 것은
user_id = 10인 모든 인덱스 엔트리- 그 사이 gap까지 전부 락
로 그 결과,
- 다른 결제 승인 대기
- 웹훅 처리 대기
- 심한 경우 데드락 상태
따라서 반드시 PK / 유니크 키 기준으로 잠그며, 범위 조건 UPDATE를 피하고, 트랜잭션을 짧게 유지하는 등의 설계 판단이 중요해집니다.
7. 락이 무서운 게 아니라, 범위를 모르는 게 무섭다
정리해보자면 다음과 같습니다.
| 상황 | 결과 |
|---|---|
| PK 기준 Record Lock | 안전 + 빠름 |
| 보조 인덱스 범위 조건 | Next-Key Lock 확산 |
| 인덱스 없음 | 테이블 전체 락 수준 |
결제 시스템은 특히 상태 전이, 중복 처리 방지, 정확한 1회 처리가 중요하기에 락을 피하는 것이 아닌 통제해야 합니다.
격리 수준(Isolation Level)은 무엇을 포기하고 무엇을 지키는가
앞서 락이 왜 생기고, InnoDB가 인덱스를 기준으로 락을 거는 이유를 살펴봤는데요. 이제 다음 질문으로 자연스럽게 이어집니다.
락을 이렇게까지 거는 이유가 결국 ‘격리 수준’을 지키기 위해서라면, 격리 수준이 정확히 뭘 의미하지?
격리 수준은 DB 이론에서 늘 등장하지만, 사용 시엔 트랜잭션 옵션 한 줄로 취급되곤 하는데요. 하지만 결제, 정산, 포인트, 재고 같은 금융·상태 기반 도메인에서는 격리 수준이 곧 시스템의 철학이 되기도 합니다.
1. 격리 수준이란 무엇인가 — 동시에 일어나는 일을 어떻게 볼 것인가
트랜잭션 격리 수준은 다음과 같이 한 문장으로 정리할 수 있습니다.
동시에 실행되는 트랜잭션을 서로 얼마나 ‘안 보이게’ 할 것인가
즉, 어떤 트랜잭션이 다른 트랜잭션의 변경을 언제, 어디까지 볼 수 있는가를 정의하는 규칙입니다.
2. 동시성 문제의 4대 유령
격리 수준은 다음과 같이 4가지 문제를 기준으로 설명됩니다.
Dirty Read→ 커밋되지 않은 데이터를 읽음Non-Repeatable Read→ 같은 쿼리를 두 번 실행했는데 결과가 다름Phantom Read→ 없던 레코드가 생김Lost Update→ 서로의 업데이트가 덮어써짐
이 중 결제 시스템에서 특히 치명적인 건 Non-Repeatable Read와 Phantom Read로 볼 수 있습니다.
READ COMMITTED — 항상 최신 커밋만 본다
먼저 READ COMMITTED부터 살펴봅시다.
동작 원리
SELECT는 항상 가장 최근 커밋된 버전을 읽음- MVCC + Undo Log로 구현
- 락은 쓰기 시점에만 강하게 사용
이는 Gap Lock 거의 사용하지 않고 Insert를 허용하며, Phantom Read가 가능한데요.
이를 결제 승인 예제와 함께 보면,
1
2
3
// Transaction A
BEGIN;
SELECT status FROM payment WHERE order_id='ORD-1'; -- AUTHORIZED
1
2
3
// Transaction B
UPDATE payment SET status='CONFIRMED' WHERE order_id='ORD-1';
COMMIT;
1
2
/* 다시 Transaction A */
SELECT status FROM payment WHERE order_id='ORD-1'; -- CONFIRMED
다음 상황에서 같은 SELECT 인데 결과값이 바뀌는 것을 확인할 수 있는데요. 이는 Non-Repeatable Read 가 발생한 상태로 볼 수 있습니다.
4. READ COMMITTED의 장점과 함정
READ COMMITTED 의 장점은 다음과 같습니다.
- 락 범위가 작다
- 동시성이 낮다
- 데드락 가능성이 낮다
하지만 결제 시스템에서 다음 로직을 생각해봅시다.
1
2
3
4
Payment p = find(orderId); // AUTHORIZED
if (p.canConfirm()) {
confirm();
}
그 사이에 다른 트랜잭션이 상태를 바꿨다면? 첫 SELECT 를 기준으로 판단하지만, 실제 UPDATE 시점에는 이미 상태가 바뀌어 비즈니스 규칙이 깨질 수 있습니다. 따라서 READ COMMITTED` 는 조회 위주 시스템이나, 통계/리포트, 캐시 기반 읽기에 더 적합합니다.
5. REPEATABLE READ — 내가 본 세계는 끝까지 유지된다
MySQL InnoDB의 기본 격리 수준은 REPEATABLE READ인데요.
트랜잭션 스냅샷 트랜잭션 시작 지점에 논리적 시점(View)를 하나로 고정하고, 이후 모든 SELECT는 이 스냅샷을 기준으로 합니다. 즉, 트랜잭션이 시작된 순간의 세계만 보는 것입니다.
즉, 이는 READ COMMITTED 와 달리 Gap / Next-Key를 적극 사용하고 Phantom Read 방지하며 락 범위가 큽니다.
같은 예제를 REPEATABLE READ로 보면
1
2
3
// Transaction A
BEGIN;
SELECT status FROM payment WHERE order_id='ORD-1'; -- AUTHORIZED
1
2
3
// Transaction B
UPDATE payment SET status='CONFIRMED' WHERE order_id='ORD-1';
COMMIT;
1
2
/* 다시 Transaction A */
SELECT status FROM payment WHERE order_id='ORD-1'; -- 여전히 AUTHORIZED
REPEATABLE READ 에서는 같은 결과값을 유지하는 것을 볼 수 있습니다. 즉, Non-Repeatable Read가 방지된 것입니다. 이게 가능한 이유는 Undo Log가 이전 버전으로 남아있고 MVCC 가 그 버전을 참조하기 때문입니다.
6. 그런데 Phantom Read는 어떻게 막을까?
REPEATABLE READ에서도 단순 SELECT는 Phantom을 막지 못합니다. 그래서 InnoDB는 한 발 더 나아갑니다.
1
2
3
SELECT * FROM payment
WHERE amount BETWEEN 10000 AND 20000
FOR UPDATE;
이 순간 Record Lock, Gap Lock, `Next-Key Lock 을 조합해 지금 본 범위를 끝까지 고정하도록 강제 보장합니다. 이게 바로 격리 수준과 락 메커니즘의 결합입니다.
7. 왜 MySQL은 REPEATABLE READ를 기본으로 선택했을까?
결제 시스템 관점에서 보면 이유는 더 명확해집니다.

즉, MySQL 은 읽기 일관성을 성능보다 더 중요한 기본값으로 선택한 것입니다. 따라서 결제에서는 REPEATABLE READ + 정확한 인덱스를 통해 정산, 집계, 상태 전이와 중간에 값이 튀는 현상 방지를 보장하고자 했습니다. 다만, 쿼리를 잘못 짜면 바로 병목이 생기기 쉽다는 단점이 있습니다.
제 상황을 다시 살펴보면,
1
2
3
@Lock(PESSIMISTIC_WRITE)
@Query("select p from Payment p where p.orderId = :orderId")
Payment lockByOrderId(String orderId);
orderId UNIQUE 인덱스로, Record Lock 1건을 유지하고 유니크이기에 Gap Lock이 발생하지 않습니다. 반대로 위험한 예시도 같이 살펴보면,
1
2
3
SELECT * FROM payment
WHERE status = 'AUTHORIZED'
FOR UPDATE;
상황에서 status 인덱스 있지만 값이 많아 수천 건의 락이 걸리며 모든 승인 요청을 대기하게 됩니다.
8. 격리 수준은 “성능 옵션”이 아니다
지금까지의 내용을 정리하자면 다음과 같습니다.
| 격리 수준 | 특징 | 결제 시스템 적합도 |
|---|---|---|
| READ COMMITTED | 최신 데이터 | 주의 |
| REPEATABLE READ | 판단 일관성 | 기본 |
| SERIALIZABLE | 완전 격리 | 과도 |
따라서 결제 구조가 명확한 상태 머신 + PK 기반 락 + 짧은 트랜잭션를 통해 REPEATABLE READ에 최적화하고자 했습니다.
Spring 트랜잭션 전파는 DB에서 어떻게 보이는가
앞 파트에서 우리는 격리 수준(REPEATABLE READ) 이 “한 트랜잭션이 바라보는 세계를 어떻게 고정하는가”에 대한 규칙임을 살펴보았습니다. 여기까지 살펴보며 다음과 같은 의문이 생겼습니다.
그럼 Spring에서 말하는 REQUIRES_NEW는 DB 입장에서 도대체 뭘 하는 거야?
이 질문에 답하지 못하면 REQUIRES_NEW는 그냥 마법의 옵션처럼 쓰이게 됩니다. 하지만 DB 관점에서 보면, 이 옵션은 매우 물리적이고 구체적인 행동을 합니다.
1. 트랜잭션 전파는 코드 옵션이 아니라 연결 제어다
Spring 트랜잭션 전파는 종종 트랜잭션 안에서 또 트랜잭션을 여는 것으로 오해됩니다. 하지만 DB에는 중첩 트랜잭션이 없습니다 (세이브포인트는 별개). Spring 트랜잭션은 새로운 무언가가 아닌, DB 트랜잭션을 언제 시작하고, 언제 끝낼지를 정하는 제어기입니다. 즉, Spring 트랜잭션 전파는 DB 커넥션을 어떻게 쓰고 DB 트랜잭션을 어디서 열고 닫을지에 대한 정책입니다.
따라서 Spring의 전파 옵션은 사실상 이 질문에 대한 답입니다.
이 메서드가 실행될 때 기존 DB 커넥션을 그대로 쓸 것인가, 새 커넥션을 빌릴 것인가?
2. REQUIRED vs REQUIRES_NEW — DB 입장에서의 차이
REQUIRED (기본값)
1
2
3
4
@Transactional
public void outer() {
inner();
}
이를 DB 관점에서 보면
- 커넥션: 1개
- 트랜잭션: 1개
- COMMIT 시점: 가장 바깥 메서드 종료 시
인 상황으로, 모두 같은 운명에 놓여있다고 볼 수 있습니다. 풀어서 이야기하자면 커밋 시점은 outer가 끝날 때로, outer가 롤백되면 inner 결과도 전부 롤백됩니다. 또한 이는 이미 트랜잭션이 있으면 거기에 올라탄다는 뜻으로, 원자성이 필요한 단일 작업에 적합합니다.
REQUIRES_NEW
1
2
3
4
@Transactional
public void outer() {
innerRequiresNew();
}
1
2
@Transactional(propagation = REQUIRES_NEW)
public void innerRequiresNew() { ... }
다음 상황은 DB에서는 이렇게 보입니다.
outer→ 커넥션 A, 트랜잭션 A 시작innerRequiresNew진입 → 커넥션 A 일시 중단, 커넥션 B 새로 획득, 트랜잭션 B 시작innerRequiresNew종료 → 트랜잭션 B 즉시 COMMIT, 커넥션 B 반납outer재개 (트랜잭션 A 계속)
따라서 완전히 독립된 두 개의 트랜잭션이 됩니다. 결국 짧은 트랜잭션을 DB 관점에서 풀면,
- 락을 잡고 있는 시간
- 커넥션을 점유하는 시간
- Undo/Redo 로그를 늘리는 시간
을 최소화한다는 뜻으로, REQUIRES_NEW는 이걸 가능하게 합니다. 즉, REQUIRES_NEW는 기존 트랜잭션을 잠시 멈추고, 완전히 새로운 트랜잭션을 연다는 뜻으로 새로운 DB 커넥션과 새로운 트랜잭션을 가지며 즉시 커밋되는 구조로 outer가 실패해도 inner는 살아남을 수 있습니다.
3. 결제 설계에서 REQUIRES_NEW가 필요한 이유
결제 흐름을 다시 떠올려봅시다.
멱등키 선점 → 결제 상태를 AUTHORIZED → PG 외부 호출 → 결과 반영 (CONFIRMED / FAILED)
이걸 하나의 트랜잭션으로 묶으면 PG 응답 지연 (= 락 유지), 타임아웃 (= 전체 롤백), 커넥션 풀 고갈 등의 상황을 초래할 수 있습니다. 즉, 외부 I/O가 DB를 인질로 잡게 됩니다.
이에 PG 승인는 외부 시스템, DB는 내부 시스템으로 PG와 DB를 하나의 트랜잭션으로 묶을 수 없다고 판단했습니다. 이를 위해 어디까지를 즉시 확정하고 어디부터를 나중에 맞출 것인가에 대한 질문이 필요합니다.
멱등키 선점 상황
1
2
3
4
5
txNew().execute(() -> {
commandRepository.save(
PaymentCommand.start(idemKey)
);
});
이 사실은 절대 되돌려지면 안 됩니다. 외부 PG가 실패하든, 서버가 죽든 이미 처리 중이라는 사실은 남아야 합니다. 따라서 REQUIRED 일 수 없었습니다.
1
2
3
4
outer TX 시작
├─ 멱등키 저장
├─ PG 호출
└─ 예외 발생 → 롤백
REQUIRED였다면 멱등키도 롤백되고, 동일 요청 재시도하며, 중복 결제 가능성이 생기는 문제가 발생합니다.
결제 예약(AUTHORIZED) 상황
1
2
3
4
5
txNew().execute(() -> {
Payment p = lockByOrderId(orderId);
p.authorized(...);
save(p);
})
해당 코드는 이 주문은 결제 프로세스에 진입했다는 의미로, 이 또한 PG 호출 결과와 무관하고 서버가 죽어도 남아야 하며 Webhook / Reconciliation의 기준점이 됩니다.
즉, 조정의 기준점(anchor)이기에 단독 커밋이 맞다고 생각했습니다.
4. REQUIRES_NEW + 외부 I/O 분리의 정확한 의미
1
2
3
4
5
6
7
[즉시 확정해야 하는 것]
- 멱등키 선점
- ‘이 요청은 처리 중이다’라는 사실
[나중에 맞춰도 되는 것]
- PG 승인 결과 반영
- 상태 최종 확정
1
2
ConfirmResult result =
paymentProvider.confirm(...); // 트랜잭션 밖
트랜잭션은 로컬 자원이고 네트워크는 비결정적이며 fsync도 못 걸고 롤백도 못 하기에 외부 I/O 분리가 정합하다 판단했습니다. DB 트랜잭션 안에 넣는 순간 락 + 커넥션 + 타임아웃 폭탄을 초래할 수 있기 때문입니다.
여기까지 살펴본 제 설계는 다음과 같습니다.

이 구조의 핵심은 DB는 항상 일관된 중간 상태를 가지는 것입니다. DB 관점에서 이는 다음과 같은 장점을 가집니다.
- 락 시간 단축: 1초짜리 PG 호출이 DB 락 시간에는 0초
- 커넥션 풀 안정성: 외부 지연이 커넥션을 잡아먹지 않음
- 실패 전파 차단: PG 장애 ≠ DB 장애
5. 그런데 왜 “과도한 REQUIRES_NEW는 위험”하다고 할까?
이 말에는 다음과 같은 조건이 있습니다.
- 중첩된 REQUIRES_NEW: 루프 안에서 수십 번
- 병렬 실행: 동시에 여러 TX 생성
- 커넥션 풀 고려 없음
이러한 경우에는 커넥션이 폭증하고, Context switching 증가하며, 데드락 가능성이 올라갑니다.
1
2
3
4
5
6
7
REQUIRES_NEW {
주문 생성
}
REQUIRES_NEW {
결제 차감
}
다음과 같은 구조에서 중간 실패 시 부분 커밋 상태가 남기 때문에, 별도의 보상 트랜잭션/재처리/상태머신이 없으면 운영 복구 비용이 급격히 커질 수 있습니다. 즉, 도메인적으로 하나의 의미인 작업을 아무 연결 고리 없이 독립 커밋 단위로 잘라버리는 것이 위험합니다.
다만, 제 케이스에서는 REQUIRES_NEW를 순차 실행하며 한 요청당 최대 2~3회로, 각 TX는 100ms 내외이며 외부 I/O는 TX 밖이기에 TX 수는 늘렸지만 동시에 열리는 TX 수는 늘어나지 않도록 했습니다.
또한,
- 상태 전이 = 도메인 메서드
- 트랜잭션 경계 = 애플리케이션 서비스
- 인프라(I/O) = 분리
상태로, 객체는 상태만 알고 트랜잭션은 객체를 감싸도록 하여 OOP 를 지키고자 했습니다.
6. 정리: REQUIRES_NEW는 도구이지 만능키가 아니다
결론적으로, REQUIRES_NEW는 DB 커넥션을 새로 잡고 트랜잭션을 즉시 확정하는 옵션으로, 외부 I/O와 결합할 때 시스템 안정성을 극적으로 높여줍니다. 하지만 무분별하면 커넥션 폭탄이 될 수 있으므로, 짧고, 독립적이며, 목적이 명확할 때만 사용해야 합니다.
완전한 원자성은 환상일지도..
앞서 REQUIRES_NEW가 DB 커넥션과 트랜잭션을 어떻게 물리적으로 분리하는지를 살펴봤습니다. 그런데 트랜잭션을 쪼개면 ACID의 A(Atomicity, 원자성)가 깨지는 거 아닌가요?
1. ACID는 신화가 아니라 범위의 문제다
DB 교과서에서 ACID는 절대 법칙처럼 등장합니다.
Atomicity(원자성)Consistency(일관성)Isolation(고립성)Durability(지속성)
하지만 여기서 중요한 질문은 어디까지를 하나의 트랜잭션으로 볼 것인지 입니다. DB 내부에서의 ACID와 시스템 전체 관점의 ACID는 다르기 때문입니다.
2. 결제 시스템에서 완전한 원자성이 어려운 이유
결제는 DB 혼자서 끝나지 않고, PG, 카드사/은행, 웹훅, 네트워크 등 외부 요소가 반드시 등장하게 됩니다. 이 순간, 분산 시스템이 됩니다.
예제: 이상적인 원자성
요청이 끝나는 순간 모든 시스템의 상태가 동일해야 하는 방식을 즉시 일관성 이라 부르며, 단일 DB, 단일 트랜잭션, 외부 의존성 없는 상황에서 자주 사용되는 개념입니다.
1
2
3
4
5
BEGIN TRANSACTION
DB 상태 변경
PG 승인
카드사 승인
COMMIT
이게 가능하려면:
- PG도 트랜잭션 참여
- 카드사도 2PC 참여
- 네트워크 장애 없음
인 상태여야 하지만, 현실에서는 어렵습니다.
3. 그래서 등장하는 개념: 최종 일관성
결제 시스템은 이렇게 정의된다.
지금 당장은 어긋날 수 있지만, 시간이 지나면 반드시 맞춰진다.
이게 바로 Eventual Consistency입니다.
REQUIRES_NEW + 외부 I/O 분리는 원자성을 포기하기 위함이 아닌 원자성의 “범위”를 재정의하기 위함임을 강조했었는데요, 중간에 서버가 죽거나, PG 응답이 늦거나, Webhook이 여러 번 오면 이 시스템은 어떻게 버티는지에 대한 질문이 생깁니다.
그리고 이 질문에 답변하는게 바로 최종 일관성(Eventual Consistency), 그리고 Webhook + 조정(Reconciliation) 입니다.
4. 결제 설계에서의 일관성 단계
따라서 구조를 다시 정리하면
1단계: DB 기준의 일관성
- Payment 상태
- CommandLog
- Ledger
모두 InnoDB 트랜잭션으로 보장합니다.
2단계: 외부 세계와의 불일치 가능성
이 순간이 문제입니다.
1
2
3
DB: AUTHORIZED
PG: 승인 완료
서버: 다운
이건 에러가 아닌 과정입니다.
| 상태 | 의미 |
|---|---|
| AUTHORIZED | 결제 프로세스 진입 |
| CONFIRMED | 승인 완료 |
| FAILED | 명시적 실패 |
| IN_PROGRESS(Command) | 아직 결과 미확정 |
5. 왜 이걸 실패라고 부르면 안 되는가
그럼 이 상태는 오류니까 전부 롤백해야 하지 않나?
라고 생각할 수 있지만, 이미
- PG 승인됨 ❌ 롤백 불가
- 카드사 승인됨 ❌ 취소 필요
이 순간부터는 보상 트랜잭션의 세계로 넘어가야 합니다.
6. 웹훅(Webhook)은 사후 처리가 아니다
여기서 중요한 인식 전환이 필요합니다. 웹훅은 장애 대응용이 아닌, 정합성 모델의 일부입니다.
PG는 이렇게 설계돼 있습니다.
- 응답 실패 가능
- 재전송 가능
- 중복 전송 가능
즉, 웹훅은 신뢰 가능한 최종 진실입니다.
왜 우리는 왜 Webhook이 더 믿을 수 있을까요?
이유는 PG 내부 상태 변화에 의해 발생하며, 네트워크 재시도 내장되어 있어 결과가 확정된 후 발송되기 때문입니다.
1
2
API 응답 = 요청의 결과
Webhook = 시스템의 상태
7. 멱등성과 웹훅의 결합
따라서 설계에는 다음이 들어가야 합니다.
eventIdUNIQUE- 이미 처리된 이벤트 무시
REQUIRES_NEW로 즉시 커밋
이게 없다면, 중복 승인, 중복 취소, 원장 2번 기록이 발생할 수 있습니다. Webhook은 at-least-once로 보내야 합니다.
1
2
3
4
PaymentEvent event =
eventRepository.findByEventId(eventId)
.orElseGet(() -> saveNewEvent());
여기서 eventId 가 바로 멱등키로 같은 이벤트는 절대 두 번 처리하지 않도록 하며 위 3가지를 보장합니다.
Webhook 처리 흐름을 다시 살펴보면 다음과 같습니다.
1
2
3
4
5
6
1. eventId 선점 (REQUIRES_NEW)
2. 이미 처리됨? → 종료
3. Payment 조회 (lockByOrderId)
4. 상태 전이
5. Ledger 반영
6. event.processed = true
8. 조정(Reconciliation)의 필요성
이제 가장 중요한 포인트는 웹훅만 있으면 충분한가? 라는 질문입니다.
웹훅 유실, 웹훅 지연, PG 장애, 내부 서버 장애 등의 상황이 발생하면 웹훅만으로는 해결할 수 없게 됩니다. 이때 조정이 필요합니다.
1
2
3
DB 상태 ≠ PG 상태
→ 비교
→ 보정
조정은 마지막 안전장치로 작용하며 다음 상황에
1
2
status = IN_PROGRESS
createdAt < now - 30 minutes
아직도 끝나지 않았다면, 뭔가 중간에 끊겼다는 의미로 조정 대상이 됩니다.
조정 로직의 핵심 흐름
1
2
3
4
5
6
7
8
9
for (PaymentCommand cmd : stuckCommands) {
PgStatus pg = pgClient.getStatus(cmd.getPaymentKey());
if (pg == CONFIRMED) {
applyConfirmResult(...);
} else if (pg == CANCELED) {
applyCancelResult(...);
}
}
여기서 중요한 점은 조정도 멱등이기에 이미 CONFIRMED면 다시 해도 안전하며 상태 전이는 단방향이라는 점입니다.
1
2
INIT → AUTHORIZED → CONFIRMED
→ FAILED
상태 전이가 다음과 같이 순서와 방향을 가지기에 같은 상태로 여러 번 가도 안전하며 재처리가 가능합니다.
9. 조정은 어떻게 동작하는가
Step 1. “의심 대상” 찾기 다음 조건을 만족하는 결제를 조회합니다.
AUTHORIZED상태- 30분 이상 경과
CommandLog = IN_PROGRESS
이는 의도가 있었지만, 결과가 확정되지 않은 결제입니다.
Step 2. PG에 상태 질의
1
GET /payments/{paymentKey}
PG 응답: CONFIRMED, CANCELED, FAILED
Step 3. DB 보정
PG = CONFIRMED → DB CONFIRMEDPG = CANCELED → DB CANCELEDPG = FAILED → DB FAILED
이때도 REQUIRES_NEW를 적용합니다. 조정은 항상 독립적으로, 즉시 커밋되어야 하기 때문입니다.
이는 다음과 같은 장점을 지니고 있습니다.
- 단일 실패 지점 없음: 웹훅 실패 → 조정, 조정 실패 → 다음 주기
- 재시도 안전: 멱등성 보장, 중복 실행 무해
- 장애 전파 차단: PG 장애 ≠ DB 장애
요약하면 다음과 같습니다.
| 항목 | 선택 |
|---|---|
| DB 내부 | 강한 ACID |
| 외부 시스템 | 최종 일관성 |
| 복구 전략 | 웹훅 + 조정 |
| 실패 허용 | 설계에 포함 |
장애 시나리오로 검증하는 결제 트랜잭션 설계
이번 파트에서는 네가 설계한 구조가 실제 장애 상황에서 어떻게 살아남는지를 현실적인 시나리오로 하나씩 검증해봅시다.
중요한 전제부터 다시 깔고 갑니다.
결제 시스템은 “실패하지 않는 시스템”이 아니라 “실패해도 망가지지 않는 시스템”이다.
시나리오 1. PG 승인 성공 → 서버 다운
1
2
3
A-2) Payment AUTHORIZED 커밋 ✅
B) PG confirm 호출 → 승인 성공 ✅
C) 결과 반영 전에 서버 프로세스 다운 ❌
이때 상태를 살펴보면 다음과 같습니다.
| 시스템 | 상태 |
|---|---|
| PG | CONFIRMED |
| 우리 DB | AUTHORIZED |
| CommandLog | IN_PROGRESS |
즉시 일관성은 깨졌다. 하지만 이건 “비정상”이 아니라 “설계된 중간 상태”입니다.
시스템은 다음과 같이 복구됩니다.
- Webhook 도착
- PG는 승인 확정 후 Webhook 전송
- 서버 재기동 후 정상 수신
1
2
3
4
PAYMENT_CONFIRMED 이벤트 수신
-> lockByOrderId
-> 상태 AUTHORIZED -> CONFIRMED
-> Ledger 기록
- Webhook까지 실패했다면?
Reconciliation배치 실행- PG 상태 조회
CONFIRMED확인 후 결과 반영
중간에 서버가 죽어도 데이터는 의미 있는 상태에 머물며, 롤백 불가능한 외부 승인과 충돌하지 않습니다.
시나리오 2. PG 타임아웃 → 실제로는 승인됨
1
2
3
B) PG confirm 호출
-> 네트워크 타임아웃 ❌
-> 서버는 실패로 인식
하지만, PG 내부 승인 성공된 상태를 가정해봅시다. 이 상황에서는 다음과 같이 동작합니다.
- PG 응답 실패 →
ConfirmResult.failure - C단계에서
FAILED상태로 저장 - CommandLog = FAILED
이 시점엔 불일치가 있습니다.
| PG | DB |
|---|---|
| CONFIRMED | FAILED |
그 다음은
- Webhook 도착 → 상태 보정
- 또는 Reconciliation → 상태 보정
으로 진행됩니다. 이때 중요한 점은 FAILED도 terminal 상태가 아닙니다.
1
2
3
if (pgStatus == CONFIRMED) {
applyConfirmResult(...)
}
그래서 실패를 끝으로 보는게 아닌, 언제든 뒤집을 수 있는 상태입니다.
시나리오 3. 사용자 연타 / 중복 요청 폭주
다음과 같은 상황을 가정해봅시다.
- 모바일 네트워크 불안정
- 사용자가 결제 버튼 5번 연속 클릭
- 동일 요청이 동시에 서버 도착
이를 위해 멱등키(Idempotency-Key)를 적용합니다. reserveIdempotencyKey(idemKey)
REQUIRES_NEWUNIQUE index- 첫 요청만 선점 성공
그 결과,
| 요청 | 결과 |
|---|---|
| 첫 요청 | 정상 처리 |
| 나머지 | CONFLICT (processing) |
PG 호출은 단 한 번만 발생하고, 중복 결제를 원천 차단합니다.
시나리오 4. Webhook 중복 수신
- PG 정책: at-least-once
- 동일 Webhook 3번 도착
다음과 같은 상황에서는 아래의 처리 흐름을 따릅니다.
findByEventId(eventId)
- 첫 번째 → 신규 생성
- 두 번째 → 이미 존재
세 번째 → 이미 processed
Ledger는 절대 중복 기록되면 안 된다- 회계 시스템은
한 번이 생명이다
eventId UNIQUE + 트랜잭션는 결국 회계 안전장치입니다.
시나리오 5. DB 데드락 발생
- 동시에 여러 주문 결제
lockByOrderId에서 데드락 발생
그 결과, InnoDB → 한 트랜잭션 강제 종료되고 Exception이 발생합니다. 이때, 해당 TX만 롤백하고 외부 PG 호출 전이므로 영향 없게 하며 클라이언트 재시도 시에는 멱등키로 안전하도록 합니다.
시나리오 6. 조정 배치 중 서버 재시작
- Reconciliation 배치 실행 중
- 중간에 서버 다운
다음 상황에서는,
- 조정 로직은 멱등
CONFIRMED → CONFIRMED재적용 가능- Ledger는 상태 기반으로 한 번만 기록
따라서 조정은 중단되어도 다시 시작 가능합니다.
시나리오 7. 트랜잭션 로그(WAL) 관점
이제 DB 내부까지 내려가 봅시다.
InnoDB는 Redo Log (WAL), Undo Log, Double Write Buffer 를 통해 커밋된 상태는 반드시 디스크에 남깁니다. 즉, REQUIRES_NEW 커밋 = 영구 상태 입니다. 그래서 서버가 죽거나, JVM 크래시가 나도, OS 재부팅이 돼도 중간 단계는 정확히 복원됩니다.
모든 시나리오의 공통점
모든 장애에서 공통으로 성립하는 진실은 트랜잭션이 짧고, 단계가 분리돼 있다는 점입니다. 그래서 롤백 범위가 작고 재시도 비용이 낮고 상태 추적이 쉽습니다.
결제 트랜잭션 설계의 핵심 요약과 철학
지금까지 트랜잭션, 락, InnoDB 내부 동작, Spring 전파, 외부 I/O, 웹훅, 조정(Reconciliation), 장애 시나리오까지 결제 시스템의 거의 모든 층위를 내려왔으며 이를 요약하자면 다음과 같습니다.
1. 결제 시스템의 본질은 상태 머신이다
결제는 단순한 CRUD가 아닙니다. 결제는 명확한 상태 전이(state transition) 를 가진 시스템입니다.
1
2
3
4
CREATED
→ AUTHORIZED
→ CONFIRMED
→ CANCELED / FAILED
이 상태 전이는 다음 규칙을 반드시 만족해야 합니다.
- 되돌릴 수 없는 방향이 존재한다
- 외부 시스템(PG)이 최종 권위자다
- 내부 DB는 외부 현실을 “추적”한다
이에 따라 상태 변경을 엔티티 내부 메서드로만 허용했습니다.
1
2
3
payment.confirmed(...)
payment.failed(...)
payment.canceled(...)
결제 상태 전이는 비즈니스 규칙이지, 서비스 로직이 아닙니다.
2. 트랜잭션은 ‘크게’가 아니라 ‘짧게’ 써야 한다
결제는 중요하니까 절대 커밋되지 않은 상태를 오래 유지하면 안 됩니다.
| 단계 | 트랜잭션 |
|---|---|
| 상태 선점 | REQUIRES_NEW |
| 내부 상태 전이 | REQUIRED |
| 외부 I/O | 트랜잭션 없음 |
| 결과 반영 | REQUIRES_NEW |
이 구조 덕분에 DB 커넥션 점유 시간 ↓ 락 유지 시간 ↓ 장애 확산 범위 ↓ 를 유지할 수 있습니다.
3. DB는 마술 상자가 아니다 (Undo / Redo / MVCC)
이 설계가 안전한 이유는 DB가 뭘 해주는지 정확히 알고 있기 때문입니다.
InnoDB가 보장하는 것
Redo Log (WAL)→ 커밋된 변경은 반드시 디스크에 남음Undo Log + MVCC→ 다른 트랜잭션은 이전 스냅샷 조회 가능Crash Recovery→ 서버 다운 후에도 커밋 상태 복원
따라서 REQUIRES_NEW 커밋 은 “되돌릴 수 없는 사실”이 됩니다. 즉, 트랜잭션을 과하게 키우거나, 의미 없이 나누면 안됩니다.
4. 락은 “테이블”이 아니라 “인덱스”에 걸린다
결제 시스템에서 락 설계는 생존 문제입니다. 따라서 lockByOrderId(orderId) 를 통해 PK 또는 UNIQUE 인덱스 기반으로 레코드 락만 획득하게 하여 갭 락을 최소화 하고자 했습니다. 인덱스를 잘못 잡으면 한 건의 결제가 수백 건을 멈출 수 있기 때문입니다.
5. REQUIRES_NEW는 “위험한 기능”이 아니라 “도구”다
결국, 사람들이 REQUIRES_NEW를 싫어하는 이유는 아무데나 쓰기 때문입니다.
REQUIRES_NEW 사용 목적 3가지
- 멱등키 선점
- 이벤트 처리 결과 기록
- 외부 실패와 내부 상태 분리
즉, 외부 세계와 내부 세계의 경계선을 긋는 용도로 사용하고자 했습니다. 이를 통해 과도한 사용인지 아닌지 살펴보고 의미있게 사용하고자 노력했습니다.
6. 즉시 일관성은 환상이고, 최종 일관성은 전략이다
DB 커밋 = 결제 완료 라는 믿음은 위험할 수 있습니다. PG 승인, 네트워크 지연, Webhook 재시도, 타임아웃, 재처리 등 현실은 항상 비동기이기 때문입니다. 따라서 지금은 어긋나 있어도 반드시 같은 상태로 수렴하고자 했습니다. 이는 바로 최종 일관성(Eventual Consistency) 입니다.
6. Webhook + Reconciliation = 보험
결제 시스템은 다음 상황으로 인해 보험이 필요합니다.
- Webhook: 실시간 복구
- Reconciliation: 최종 복구
이 둘을 통해 서버 다운, 메시지 유실, 타임아웃 등의 상황을 시스템적 사고로 흡수할 수 있습니다. 이를 통해 여러 번 실패해도 결국 맞아야 하도록 노력했습니다.
힘드네요.. 2부도 쓰도록 하겠습니다..