메모리 모델 (Stack, Heap, Method Area)
JVM Stack: 실행 흐름은 어디에 기록되는가
1. JVM Stack의 위치와 역할
JVM Stack은 단순히 지역 변수 저장소가 아니라, 자바가 플랫폼 독립적인 언어로 설계될 수 있었던 핵심 구조다. JVM은 특정 CPU 아키텍처의 레지스터 구조를 전제로 하지 않는다. 대신 모든 연산을 스택 기반으로 추상화해 바이트코드만으로 서로 다른 하드웨어에서 동일한 실행 의미를 보장한다. 이 결정은 성능보다 이식성과 일관성을 우선한 선택이었고, 이후 JIT 컴파일러가 등장하면서 JVM은 스택 기반 추상 머신 위에 레지스터 기반 실행을 덧씌우는 구조로 진화했다.
JVM Stack은 자바 프로그램 실행의 실질적인 무대다. Heap이 객체의 저장소라면, Stack은 그 객체들이 어떻게, 어떤 순서로, 어떤 문맥에서 사용되는지를 결정한다. JVM이 레지스터 기반 VM이 아닌 스택 기반 VM이기 때문에 연산·호출·반환의 흐름이 Stack을 중심으로 설계다.
또한 JVM Stack은 스레드마다 독립적으로 생성된다. 즉 Stack은 thread-private memory이며, 동기화 비용이 원칙적으로 발생하지 않는다. 한 스레드의 Stack에 다른 스레드가 접근하는 것은 JVM 사양상 불가능하다. 스레드가 생성되면 JVM은 해당 스레됐tack을 할당하고, 스레드가 종료되면 Stack 전체를 한 번에 회수한다. 이 구조 때문에 Stack 메모리는 GC 대상이 아니다. 관리 비용이 낮고, 생명주기가 예측 가능하다.
Stack과 PC Register의 관계
각 스레드는 JVM Stack과 함께 PC Register를 가진다. PC Register는 현재 실행 중인 바이트코드 명령어의 주소를 저장한다. 메서드 호출이 발생하면 PC Register는 새로운 메서드의 첫 바이트코드를 가리키도록 변경된다.
중요한 포인트는 Stack Frame이 다음에 실행할 명령어 위치를 직접 들고 있지 않다는 점이다. 이 정보는 PC Register가 관리하고, Stack Frame은 실행 문맥(context)만을 보존한다. 이 분리 덕분에 JVM은 호출과 복귀를 빠르게 처리할 수 있다.
Thread-Private Memory로서의 Stack
Stack은 스레드 전용 메모리다. Stack에 저장된 데이터는 해당 스레드에서만 접근 가능하고, 다른 스레드가 이를 직접 참조하는 것은 불가능하다. 그래서 Stack 영역의 변수(지역 변수, 매개변수, 메서드 내부 임시 값)는 원칙적으로 별도의 동기화 없이도 안전하다. JMM(Java Memory Model)에서 말하는 happens-before 관계는 Stack 내부에서는 문제가 되지 않는다. 다만, Stack에서 Heap 또는 Method Area로 나가는 경계(공유 메모리로의 쓰기/읽기)에서부터 JMM 규칙이 의미를 갖는다.
2. Stack Frame의 구조
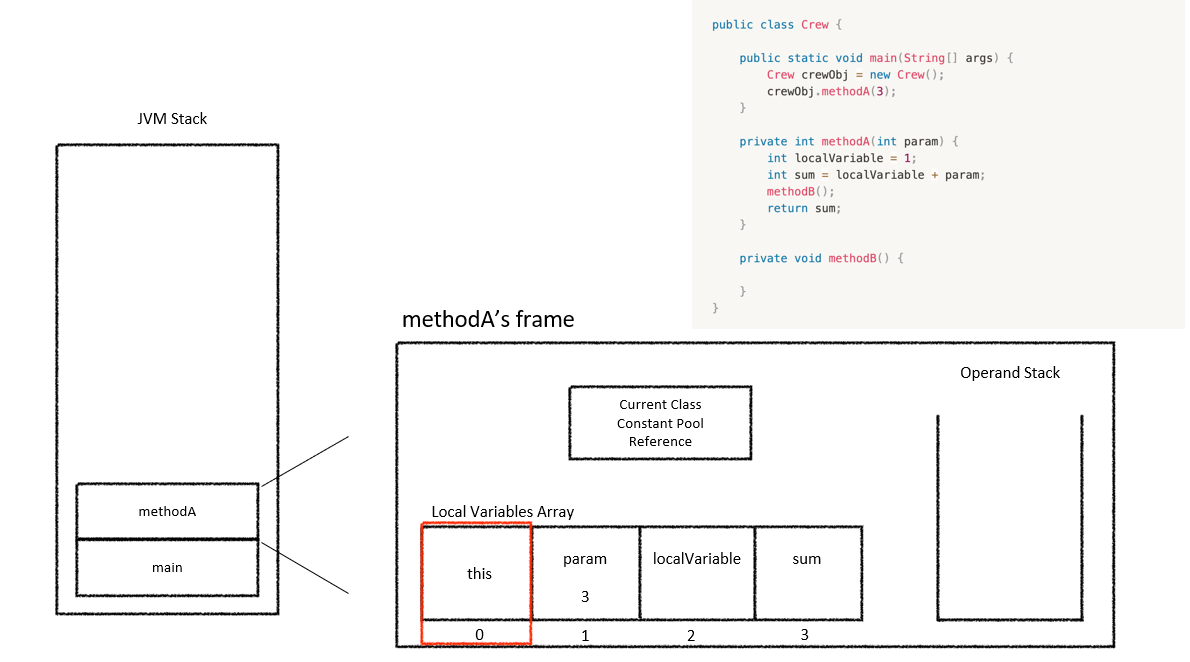
JVM Stack은 단순한 값 저장소가 아니라 Stack Frame의 연속이다. Stack Frame 하나가 메서드 실행의 최소 단위이며, 메서드 호출 1번 = Stack Frame 1개 생성, 메서드 종료 = Frame pop이 정확히 일치한다. 즉 JVM에서 어떤 메서드가 실행 중이라는 말은 그 메서드의 Stack Frame이 현재 Stack 위에 존재한다는 뜻이다.
각 Stack Frame은 크게 Local Variable Array, Operand Stack, Frame Data의 세 부분으로 구성된다.
2-1. Local Variable Array
Local Variable Array는 메서드의 매개변수와 지역 변수를 저장하는 영역이며, slot 단위로 관리된다.
int,float,reference는1 slotlong,double은2 slot
여기서 중요한 건 크기 기준이 아니라 JVM 규칙 기준이라는 점이다. 예를 들어 boolean, byte, short, char는 내부적으로 int처럼 취급되어 1 slot을 차지한다.
참조 타입 변수는 객체 자체가 아니라 Heap 객체를 가리키는 참조값만 저장한다.
1
User user = new User();
위 코드에서 new User()로 생성된 객체는 Heap에 저장되고, user 변수는 Local Variable Array에 참조값 1 slot으로 저장된다. 그래서 메서드가 종료되어 Stack Frame이 사라져도 Heap 객체는 즉시 사라지지 않을 수 있다. Stack은 값을 보관하고, Heap은 객체를 소유한다.
Local Variable Array의 실제 의미: 슬롯 재사용
Local Variable Array는 단순히 변수를 쌓아두는 공간이 아니다. JVM은 변수의 스코프가 끝나면 해당 slot을 재사용할 수 있다. 컴파일 시점에 생성되는 Local Variable Table은 디버깅을 위한 정보일 뿐, 실행 시 JVM이 slot을 어떻게 재사용할지는 별개다. 이 때문에 다음과 같은 오해가 자주 생긴다.
- 스코프가 끝났다고 해서 참조가 즉시 사라지는 건 아니다(재사용되기 전까지 slot에 남아 있을 수 있다).
- GC 관점에서 중요한 건
변수 스코프가 아니라도달 가능(reachable)여부다. - 이 구조는 Stack 메모리 증가를 막는 대신, 객체 생존 시점을 개발자가 직관적으로 오해하게 만들 수 있다.
2-2. Operand Stack
Operand Stack은 JVM 연산의 중심이다. 산술 연산, 비교 연산, 조건 분기, 메서드 호출 인자 전달, 반환값 처리까지 대부분이 Operand Stack의 push/pop으로 표현된다.
기본 패턴은 다음과 같다.
- Local Variable에서 값을 가져와 Operand Stack에
push - 연산 수행(필요한 만큼
pop) - 결과를 Operand Stack에
push - 필요하면 Local Variable에 다시
store
예시
1
2
3
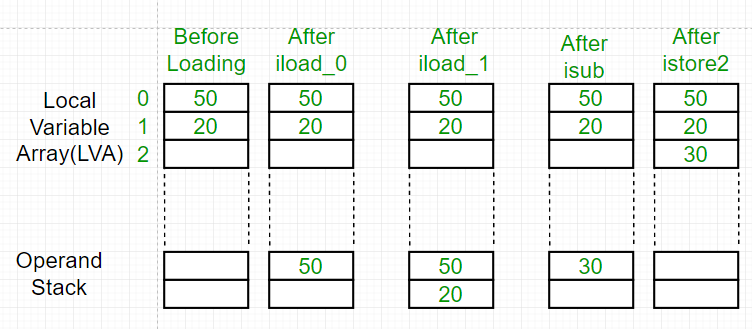
int a = 10;
int b = 20;
int c = a + b;
바이트코드 관점 흐름 (개념적으로)
1
2
3
4
iload_1 // a push
iload_2 // b push
iadd // pop a,b -> push (a+b)
istore_3 // c store
조금 더 복합
1
2
3
int x = 3;
int y = 4;
int z = x * y + 2;
개념적 흐름은 x push -> y push -> imul -> 2 push -> iadd -> store로 이어진다.
레지스터를 안 쓰는 이유
JVM 바이트코드는 플랫폼 독립성을 최우선으로 설계되었기 때문에 CPU 레지스터 구조에 의존하지 않는다. 대신 Stack 기반 실행 모델을 채택했다. 다만, JIT 이후에는 HotSpot이 값을 실제 CPU 레지스터에 할당해 레지스터 기반 머신 코드로 최적화한다. 그래서 JVM은 실행 초반(Interpreter)은 stack machine처럼, 최적화 이후는 register machine처럼 동작한다.
또 하나의 포인트
Operand Stack의 최대 깊이(max_stack)는 컴파일 시점에 계산되어 클래스 파일에 저장된다. JVM은 이를 검증에 활용한다.
2-3. Frame Data
Frame Data에는 메서드 호출과 복귀를 가능하게 하는 메타 정보가 들어간다. 대표적으로:
Runtime Constant Pool참조: 메서드 호출, 필드 접근, 문자열 리터럴 해석(심볼 참조 해결)에 사용Return Address: 메서드 종료 후 돌아갈 위치Exception Handling정보: try-catch 처리에 사용
정리하면 아래처럼 이해하면 된다.
| 구성 요소 | 역할 |
|---|---|
| Local Variable Array | 매개변수·지역 변수 저장 |
| Operand Stack | 연산/계산/인자 전달/반환값 처리 |
| Frame Data | 호출·복귀·상수풀·예외 처리 메타 정보 |
3. Stack과 메서드 호출
메서드 호출은 단순한 점프가 아니라, Stack에 새로운 Frame을 쌓는 작업이다. 호출 시 JVM이 하는 일은 크게 다음 흐름으로 이해하면 된다.
- 호출자의 Operand Stack에 인자를
push - 새로운 Stack Frame 생성
- 인자를 새 Frame의 Local Variable Array로 복사
- PC Register가 호출 대상 메서드의 바이트코드 시작 지점을 가리키도록 변경
호출 깊이가 깊어질수록 Frame이 누적되며, 과도한 재귀에서 StackOverflowError가 발생한다. 이는 Heap 부족과 무관하게 Frame을 더 만들 수 없을 때 발생한다.
호출 비용과 인라이닝
Stack Frame 생성/제거는 Heap 할당/해제보다 훨씬 가볍다(LIFO pop으로 즉시 제거되고 GC가 개입하지 않는다). 하지만 호출 자체가 0비용은 아니다. 그래서 JIT는 작은 메서드에 대해 인라이닝을 적극적으로 수행한다.
1
2
3
4
int add(int a, int b) {
return a + b;
}
int result = add(1, 2);
인라이닝이 되면 새 Frame 생성, 호출/복귀, 인자 이동 비용이 사라질 수 있다. 즉, JVM은 논리적 스택 모델 위에서 실제 실행 구조를 유연하게 바꿔 성능을 끌어올린다.
4. primitive 타입과 Stack
primitive는 값 자체가 Stack(Local Variable/Operand Stack)에 놓인다. 연산도 대부분 Operand Stack 내부에서 끝나며, Heap 접근이 필요 없다. 그래서 수치 계산·반복 연산에서는 primitive가 유리하다. 핵심은 언어 취향이 아니라 메모리 모델 관점의 차이다.
5. reference 타입과 Stack
reference 타입 변수는 Stack에 저장되지만, 그건 객체가 아니라 Heap 객체를 가리키는 참조값이다. 그래서 reference 연산은 Stack에서 참조를 이동시키고, 실제 데이터 접근은 Heap에서 일어난다. 이때 비용은 주로 pointer chasing, cache miss, GC 추적 대상 증가, Stack -> Heap 경계 접근에서 발생한다.
1
obj.field++;
개념적으로는 obj 참조 로드 -> Heap 객체 접근 -> 필드 로드/수정의 흐름이 된다.
6. Stack과 컬렉션 사용의 관계
컬렉션 객체는 Heap에 있고, Stack에는 컬렉션을 가리키는 참조만 있다.
1
List<Integer> list = new ArrayList<>();
실제 접근 경로는 보통 Stack(list 참조) -> Heap(ArrayList) -> Heap(Object[] elementData) -> Heap(Integer 객체들)처럼 이어진다. LinkedList는 Node 체인이 추가되어 경로가 더 깊어진다.
1
Map<String, List<Integer>> map = new HashMap<>();
여기서도 Stack에는 map 참조만 있고, 실제 구조는 Heap(HashMap) -> table(Node[]) -> Node -> List -> 내부 배열 같은 형태로 이어진다. Stack은 진입점일 뿐이지만, Stack Frame이 유지되는 동안 이 참조 그래프가 유지되고, Frame이 소멸되면 지역 변수로만 참조되던 객체는 GC 후보가 된다.
7. Iterator와 Stack Frame
for-each는 내부적으로 Iterator로 컴파일된다.
1
2
3
for (Integer i : list) {
sum += i;
}
개념적으로
1
2
3
4
5
Iterator<Integer> it = list.iterator();
while (it.hasNext()) {
Integer i = it.next();
sum += i;
}
Stack 관점에서는 iterator(), hasNext(), next() 호출이 반복되며 Frame 생성/제거가 누적된다. JIT가 인라이닝을 충분히 못 하면 호출 밀도가 성능에 영향을 줄 수 있고, 단순 루프에서 인덱스 기반 접근이 유리한 경우가 생기는 이유가 여기에 있다.
8. Stack과 예외 처리
예외는 Stack을 거슬러 올라가며 처리된다. 예외가 발생하면 JVM은 현재 Frame의 예외 테이블을 확인하고, 처리할 수 없으면 Frame을 pop하며 상위 호출자로 이동한다. 이 과정을 stack unwinding이라 한다. 예외가 비싼 이유 중 하나는 이 과정에서 여러 Frame이 한 번에 제거되고, finally 보장 때문에 추가적인 제어 흐름 처리가 들어갈 수 있기 때문이다. 그래서 성능 민감한 경로에서는 예외를 제어 흐름으로 남용하지 않는 게 중요하다.
9. Stack과 Escape Analysis
JIT는 escape analysis로 객체가 메서드 밖으로 탈출하는지 분석한다.
- 탈출하지 않으면: Heap 할당을 피하거나,
scalar replacement로 분해해 레지스터/스택에 두는 최적화가 가능 - 다른 스레드로 전달되면: Heap 할당이 필요
1
2
Point p = new Point(1, 2);
return p.x + p.y;
상황에 따라 p 자체가 Heap에 실제로 할당되지 않을 수도 있다(최적화 가능).
10. Stack의 한계와 설계 의의
Stack은 빠르지만 크기가 제한적이고, 기본적으로 동적 확장 대상이 아니다. 크기는 -Xss로 조절한다. Stack 크기는 스레드 수와 트레이드오프 관계가 있어서 서버 환경에서는 동시성 모델 설계의 일부가 된다.
- Stack이 크면: 깊은 호출 가능, 하지만 스레드 수 감소
- Stack이 작으면: 스레드 수 증가, 하지만 StackOverflow 위험 증가
11. Stack과 JMM(Java Memory Model)
JMM이 다루는 핵심은 공유 메모리에서의 가시성·순서·원자성이다. Stack은 스레드 전용이므로 Stack 내부 값 자체는 JMM의 문제 공간 밖에 있다. volatile, synchronized, final의 의미는 Stack이 아니라 Stack에서 Heap/Method Area로 나가는 경계에서 생긴다.
1
2
int x = 10;
int y = x + 1;
이 코드는 Stack 내부에서 끝나므로 다른 스레드와의 가시성 문제가 없다.
1
shared.value = 10;
여기서부터는 Heap에 대한 write가 발생하므로 JMM 규칙이 적용된다. volatile write는 메모리 장벽을 통해 이전 연산의 가시성과 순서를 보장하고, synchronized는 모니터 경계에서 flush/visibility를 보장한다. 즉, 이들은 Stack 내부를 보호하는 게 아니라 공유 메모리 경계를 제어한다.
12. Stack의 역할 정리
Stack은 실행 흐름을 표현하고, 스레드 독립성을 보장하며, JIT 최적화의 주요 타깃이 되고, Heap 접근의 진입점 역할을 한다. Stack을 실행 관점에서 이해해야 Heap 구조, 컬렉션의 메모리 특성, 동시성 비용을 같은 그림으로 설명할 수 있다.
Method Area: 클래스는 언제 로드되고 어디에 머무는가
1. Method Area의 위치와 역할
Method Area는 JVM이 클래스 단위 메타데이터를 올려두는 영역이다. Stack이 실행 컨텍스트(프레임)를, Heap이 인스턴스(객체)를 담당한다면, Method Area는 그 둘이 동작하기 위한 설계도를 제공한다. 즉, new로 객체를 만들기 전에 JVM은 먼저 이 클래스가 무엇인지를 알아야 하고, 그 정보가 들어 있는 곳이 Method Area다.
Method Area는 본질적으로 프로세스 공유 성격을 가진다. 동일 JVM 안에서 로딩된 클래스의 메타데이터는 모든 스레드가 함께 쓴다. 그래서 Method Area를 이해할 때의 키워드는 클래스 로딩, 런타임 상수 풀, 정적(static), 동적 링크(linking), 그리고 언로딩(unloading)이다.
자바에서 클래스는 코드 그 자체가 아니라, 실행 중에는 Class 객체(힙) + 그 Class 객체가 가리키는 클래스 메타데이터(Method Area)라는 2단 구조로 나타난다. 즉, 개발자가 MyClass.class를 쥐고 있는 순간에도, 실제로 참조하는 정보의 대부분은 Method Area에 있다.
2. Method Area에 저장되는 정보
Method Area에 저장되는 건 인스턴스의 값이 아니다. 클래스의 구조다. 대표적으로 다음이 들어간다.
클래스/인터페이스 구조
- 클래스 이름, 접근 제어자, 패키지, 상속/구현 관계
- 필드 시그니처(이름, 타입, 접근 제어자), 어노테이션 메타데이터
- 메서드 시그니처(파라미터/리턴 타입), 예외 선언, 접근 제어자
메서드 실행을 위한 정보
- 메서드 바이트코드(혹은 그에 준하는 내부 표현)
- 스택 프레임 크기 계산에 필요한
max_stack,max_locals - 예외 테이블(exception table)과 라인 넘버 테이블 같은 디버그/검증 정보
런타임 상수 풀(Runtime Constant Pool)
- 문자열 리터럴, 숫자 상수
- 필드/메서드/클래스 심볼 참조(처음엔
이름 기반으로 저장됨) - 동적 링크 과정에서 실제 주소/핸들로 해석(resolution)되며, 이후 재사용됨
동적 디스패치(가상 호출)를 위한 테이블
vtable/itable성격의 호출 디스패치 메타데이터invokevirtual,invokeinterface가 빠르게 대상 메서드를 찾기 위한 구조
static 관련 데이터
static필드 자체는 JVM/구현에 따라 위치가 달라지지만, 중요한 건클래스에 귀속되는 값이라는 점이다.static final상수의 일부는 컴파일 타임 상수로상수 풀에 인라인될 수 있다(아래 코드로 확인).
여기서 어디에 물리적으로 놓이냐는 HotSpot 버전/옵션에 따라 달라질 수 있다. 하지만 블로그 글에서 더 중요한 건, 생명주기와 공유 범위다. Method Area의 데이터는 클래스 로딩부터 클래스 언로딩까지 살아 있다.
3. 클래스 로딩이 Method Area를 채우는 과정
클래스 로딩은 한 번에 끝나는 이벤트가 아니라, 대체로 Loading → Linking → Initialization 흐름으로 이해하면 가장 안전하다.
3.1 Loading: 바이트코드가 들어오는 순간
ClassLoader가 .class 바이트를 읽어 들이면, JVM은 그 내용을 파싱해 클래스 메타데이터를 Method Area에 생성한다. 이때 힙에는 개발자가 보는 java.lang.Class 인스턴스도 만들어진다.
아래 코드는 언제 로딩이 일어나는지를 체감하는 가장 빠른 방법이다.
1
2
3
4
5
6
7
8
9
10
11
12
13
public class LoadTiming {
static class A {
static { System.out.println("A <clinit>"); }
static int x = 1;
}
public static void main(String[] args) throws Exception {
System.out.println("1) main start");
Class<?> c = Class.forName("LoadTiming$A"); // 로딩 + 초기화까지 유발
System.out.println("2) after forName: " + c.getName());
System.out.println("3) A.x = " + A.x);
}
}
Class.forName은 기본적으로 초기화까지 트리거한다. 반면 ClassLoader.loadClass는 로딩만 하고 초기화는 미루는 케이스가 많다(정확한 동작은 구현/옵션에 따라 달라질 수 있지만, 감각은 이렇게 잡으면 된다).
3.2 Linking: 검증/준비/해결
Linking은 대개 3단계다.
Verify
- 바이트코드가 JVM 규칙을 지키는지 검증한다.
- 이 단계 덕분에 JVM은 네이티브처럼 위험한 점프를 못 하게 막는다.
Prepare
static필드에 메모리를 할당하고 기본값(0, null 등)으로 초기화한다.- 아직 개발자가 쓴
= ...초기화는 실행되지 않는다.
Resolve
- 상수 풀에 있던
심볼 참조(이름 기반)가 실제 런타임 구조로 연결된다. - 이 작업은 “링킹 시점에 전부”가 아니라, 호출/접근 시점에
지연(lazy)으로 일어날 수도 있다.
3.3 Initialization: <clinit> 실행
초기화는 컴파일러가 만든 클래스 초기화 메서드 <clinit>가 수행되는 순간이다. static {} 블록과 static 필드 초기화 식이 여기에 들어간다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
public class InitOrder {
static int a = print("a");
static { print("static block"); }
static int b = print("b");
static int print(String s) {
System.out.println(s);
return 0;
}
public static void main(String[] args) {
// 클래스가 초기화되면 위 출력이 순서대로 발생
System.out.println("done");
}
}
이 초기화는 클래스당 한 번만 일어난다. 그래서 Method Area는 “한 번 준비되면 여러 번 재사용되는” 성격을 가진다.
4. 런타임 상수 풀: 말로 끝내지 말고 코드로 확인하기
상수 풀은 “컴파일 타임 상수”와 “런타임 해석(링킹)”이 섞이는 지점이라, 설명이 늘 애매해진다. 그래서 코드를 두 개만 붙여서 결을 잡자.
4.1 static final 컴파일 타임 상수 인라인
1
2
3
4
5
6
7
8
9
public class ConstInline {
public static final int PORT = 8080; // 컴파일 타임 상수
public static final Integer BOXED = 8080; // 객체라 인라인 보장 X
public static void main(String[] args) {
System.out.println(PORT);
System.out.println(BOXED);
}
}
PORT는 컴파일러가 상수 풀에 값을 박아두고 사용처에 인라인할 수 있다. 반면 BOXED는 객체 생성/참조가 걸리면서 인라인 규칙이 달라진다. 그래서 “상수 수정했는데 다른 모듈이 안 바뀐다” 같은 사고가 보통 컴파일 타임 상수 인라인에서 나온다.
4.2 문자열 상수 풀과 intern()
1
2
3
4
5
6
7
8
9
10
11
12
public class StringPool {
public static void main(String[] args) {
String a = "hello";
String b = "he" + "llo"; // 컴파일 타임 결합
String c = new String("hello"); // 힙 객체
String d = c.intern(); // 풀에 있는 참조로 정규화
System.out.println(a == b); // true
System.out.println(a == c); // false
System.out.println(a == d); // true
}
}
문자열 풀은 Java 버전마다 내부 위치/관리 방식이 변해왔지만, 개발자가 가져가야 하는 결론은 일정하다. 리터럴은 풀에 들어가고, new String은 별도 객체를 만들며, intern()은 “풀의 대표 참조”로 맞춘다. Method Area를 이해할 때 상수 풀이 중요한 이유는, 결국 이 상수들이 클래스 로딩/링킹과 강하게 엮이기 때문이다.
5. PermGen이 사라지고 Metaspace가 등장한 이유
HotSpot에서는 오래전 PermGen이라는 고정 크기 영역에 클래스 메타데이터를 넣었다. 그런데 클래스가 많은 서버(특히 동적 프록시, 리플렉션, JSP/템플릿, OSGi)에서 PermGen이 자주 터졌다. 그래서 Java 8부터는 클래스 메타데이터를 Metaspace로 옮기고, OS 네이티브 메모리를 사용하도록 바뀌었다.
핵심 변화는 이거다.
- 예전: PermGen은 힙과 비슷한 “고정 크기” 느낌이라,
PermGen spaceOOME가 잦았다. - 지금: Metaspace는 기본적으로 “필요하면 늘어나는” 방향이라, 한동안은 편해진다.
- 대신: 무제한으로 늘면 결국 OS 메모리를 잡아먹고 다른 형태의 OOM으로 이어질 수 있다. 그래서 상한을 걸어야 할 때가 생긴다.
자주 보는 에러는 이거다.
java.lang.OutOfMemoryError: Metaspace
이건 “힙이 꽉 찬 것”이 아니라, “클래스 메타데이터가 더 이상 들어갈 수 없는 것”이다. 보통 클래스 로더 누수가 원인이다.
6. 클래스 언로딩과 ClassLoader 누수
Heap은 GC가 돌면서 계속 정리된다. 하지만 Method Area(특히 Metaspace)는 클래스가 언로딩될 때만 줄어든다. 그럼 언로딩 조건은 무엇일까?
대체로 다음이 충족돼야 한다.
- 해당 클래스를 로딩한
ClassLoader가 더 이상 참조되지 않아야 한다. - 그 ClassLoader가 로딩한 클래스들도 더 이상 살아 있으면 안 된다.
- GC가
ClassLoader를 회수할 수 있어야 한다.
여기서 실무에서 가장 흔한 사고가 ClassLoader 누수다. 예시는 많지만, 패턴은 비슷하다.
나쁜 패턴
- 어떤 라이브러리가
static필드에ClassLoader가 로딩한 클래스/리플렉션 캐시/ThreadLocal을 꽂아둔다 - 웹 앱이 재배포되면서 새로운 ClassLoader가 생기는데, 예전 로더가 계속 살아 있다
- Metaspace가 계속 늘다가
OutOfMemoryError: Metaspace로 터진다
ThreadLocal은 특히 함정이다. 스레드 풀을 쓰면 스레드가 오래 살아 있고, ThreadLocal에 들어간 값이 웹앱 클래스에 대한 참조를 잡고 있으면 로더가 안 죽는다.
이 문제는 “Method Area가 커졌다”가 아니라, 더 정확히는 “언로딩이 안 됐다”다.
7. 동적 프록시, 리플렉션, 람다와 Method Area
Method Area가 급격히 커지는 케이스는 보통 “클래스가 많이 만들어질 때”다.
- JDK 동적 프록시(
Proxy.newProxyInstance)는 조건에 따라 프록시 클래스를 생성한다. - 바이트코드 생성 라이브러리(ByteBuddy, CGLIB 등)는 런타임에 클래스 자체를 만든다.
- 람다도 내부적으로는 합성 클래스/메서드 핸들로 최적화되지만, 상황에 따라 클래스 로딩과 연결된다.
즉, “객체가 많아서 힙이 터진다”와 별개로 “클래스가 많아서 메타스페이스가 터진다”는 완전히 다른 축의 문제다. 이 둘을 구분해야 튜닝 방향이 잡힌다.
8. 관측 방법: 지금 Method Area가 왜 커졌는지 보는 법
글로만 끝내면 다시 감으로 돌아간다. 아래는 최소한의 관측 포인트다.
현재 메타스페이스 사용량 확인(개념)
jcmd <pid> VM.native_memory summaryjcmd <pid> GC.class_stats(환경에 따라 제공/권한 이슈 가능)
클래스 로딩 추이
-Xlog:class+load=info,class+unload=info(JDK 9+)- 로딩만 계속되고 언로딩 로그가 거의 없으면, 언로딩 조건이 안 맞는 상황을 의심한다.
상한/튜닝 플래그(필요할 때만)
-XX:MaxMetaspaceSize=256m(상한)-XX:MetaspaceSize=128m(초기 트리거)- 무조건 작게 거는 게 아니라, “누수 탐지용으로 상한을 걸어 빨리 터뜨리는” 전략도 실무에서 자주 쓴다.
9. Method Area를 이해하면 뭐가 달라지나
Method Area는 성능과 장애에서 생각보다 자주 튀어나온다.
힙은 널널한데 OOM이 나면 Metaspace를 의심해야 한다.- 재배포/플러그인 구조/템플릿 엔진을 쓰는 앱은
ClassLoader 누수를 반드시 경계해야 한다. static한 줄이 클래스 생명주기를 고정시키고, 언로딩을 막을 수 있다.
정리하면, Method Area는 “클래스가 살아 있는 동안 유지되는 공유 설계도”다. Stack/Heap만 보면 놓치는 문제(특히 클래스 로더/메타스페이스)를 Method Area가 설명해준다.
Heap: 객체는 왜 죽지 않고, 누가 살려두는가
1. Heap은 공간이 아니라 객체 그래프다: Root 경로를 코드로 드러내기
GC는 스코프를 모른다. GC는 루트에서 도달 가능한가만 본다. 이걸 가장 짧게 확인하는 예시는 지역 변수만 잡고 있다가 스코프가 끝나면 끊기는 케이스다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
public class ReachabilityDemo {
static class User { byte[] payload = new byte[20 * 1024 * 1024]; } // 20MB
static void localOnly() throws Exception {
User u = new User(); // Heap에 객체 생성
System.out.println("allocated: " + u);
Thread.sleep(1000); // 잠깐 대기 (관찰용)
}
public static void main(String[] args) throws Exception {
localOnly(); // 스코프 끝나면 u 경로 끊김(대개)
System.gc(); // 데모용 (보장X)
Thread.sleep(2000);
System.out.println("done");
}
}
위 코드는 대개 수거된다. 하지만 문제가 되는 건 대개가 아니라 안 끊기는 경로다. 다음 섹션에서 그 경로들을 만든다.
2. Root가 길어지면 객체는 안 죽는다: static / ThreadLocal / listener
2-1. static 컬렉션: 가장 흔한 ‘의도치 않은 영생’
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
import java.util.*;
public class StaticCacheLeak {
static final List<Object> CACHE = new ArrayList<>();
static class Data { byte[] payload = new byte[10 * 1024 * 1024]; } // 10MB
static void load() {
Data d = new Data();
CACHE.add(d); // Root: static -> ArrayList -> Object[] -> Data
}
public static void main(String[] args) throws Exception {
for (int i = 0; i < 10; i++) load();
System.out.println("cache size=" + CACHE.size());
System.gc();
Thread.sleep(2000);
System.out.println("still alive because root path is static CACHE");
}
}
메서드 스코프는 끝나도 static Root 경로가 남는다. “참조 하나”라도 Root에서 닿으면 끝이다.
2-2. ThreadLocal: 지역 변수 느낌인데 실제론 스레드 생존에 붙는다
서버 스레드풀처럼 스레드가 오래 살면 ThreadLocal 값도 오래 산다. 특히 remove()를 안 하면 요청 단위 메모리가 남는다.
1
2
3
4
5
6
7
8
9
10
11
12
13
public class ThreadLocalLeak {
static final ThreadLocal<byte[]> TL = new ThreadLocal<>();
static void handleRequest() {
TL.set(new byte[20 * 1024 * 1024]); // 20MB
// TL.remove(); // 이걸 빼먹으면 스레드가 살아 있는 동안 메모리도 남을 수 있음
}
public static void main(String[] args) {
for (int i = 0; i < 100; i++) handleRequest();
System.out.println("done");
}
}
실무 팁: 요청 스코프에서 ThreadLocal을 쓴다면 try/finally로 remove()를 강제하자.
2-3. listener/callback: 등록은 Root 경로를 만드는 행위다
이벤트 소스가 리스너를 컬렉션으로 보관하는 순간, 리스너가 캡처한 객체까지 함께 묶인다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
import java.util.*;
public class ListenerLeak {
interface Listener { void onEvent(); }
static class EventSource {
private final List<Listener> listeners = new ArrayList<>();
void add(Listener l) { listeners.add(l); }
void fire() { listeners.forEach(Listener::onEvent); }
}
static class BigScreen {
byte[] payload = new byte[50 * 1024 * 1024]; // 50MB
void render() {}
}
public static void main(String[] args) {
EventSource src = new EventSource();
BigScreen screen = new BigScreen();
// 리스너가 screen을 캡처 -> src가 살아 있는 동안 screen도 살아 있음
src.add(screen::render);
screen = null; // 지역 변수는 끊겼지만, 캡처 경로는 남아 있음
System.gc();
src.fire();
System.out.println("screen is still reachable via listener list");
}
}
정리: GC는 “해제해야 한다”는 의도를 모른다. 엣지를 끊는 코드가 있어야 한다.
3. 컬렉션은 객체 그래프의 허브다: ArrayList / LinkedList / HashMap을 코드로 분해하기
3-1. ArrayList: remove 했는데도 메모리가 줄지 않는 가장 흔한 이유
ArrayList의 핵심은 size와 capacity(elementData.length)가 다르다는 것이다. remove는 size를 줄이지만, capacity(배열 덩어리)를 자동으로 줄이지 않는다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
import java.util.*;
public class ArrayListCapacityDemo {
public static void main(String[] args) {
ArrayList<byte[]> list = new ArrayList<>(1_000_000); // capacity 크게 잡기
for (int i = 0; i < 100_000; i++) list.add(new byte[1024]); // 1KB
// 대부분 제거
list.subList(1, list.size()).clear();
// size는 거의 1이지만 내부 배열(capacity)은 여전히 매우 클 수 있음
System.out.println("size=" + list.size());
// 필요하다면:
list.trimToSize(); // 내부 배열을 size에 맞춰 재할당(비용 있음)
System.out.println("trimmed");
}
}
실무 포인트: 장수하는 리스트 + 순간적으로 크게 불었다가 줄어드는 패턴열 capacity 때문에 힙을 오래 붙잡는다.
3-2. LinkedList: Node 지옥을 눈으로 보이게 만들기
LinkedList는 요소마다 Node 객체가 생기고, Node는 prev/next/item을 가진다. 즉 요소 수만큼 객체 수가 추가로 늘고 참조도 늘어난다.
1
2
3
4
5
6
7
8
9
10
11
import java.util.*;
public class LinkedListNodeDemo {
static class Box { byte[] payload = new byte[256]; } // 작은 객체
public static void main(String[] args) {
LinkedList<Box> list = new LinkedList<>();
for (int i = 0; i < 1_000_000; i++) list.add(new Box());
System.out.println("done: " + list.size());
}
}
같은 100만 개라도 ArrayList<Box>는 배열 + Box인데, LinkedList<Box>는 Node 100만 + Box 100만이다. 이 차이는 GC의 mark 단계에서 그대로 비용으로 돌아온다.
3-3. HashMap/HashSet: 중복 제거/빠른 조회 뒤에 숨은 그래프
HashMap은 버킷 배열(table) + 엔트리(Node)들로 구성된다. 엔트리 수가 늘면 Node 객체도 늘고, 리사이징이 발생하면 table이 재할당된다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
import java.util.*;
public class HashMapResizeDemo {
public static void main(String[] args) {
int n = 1_000_000;
// 예상 크기를 알면 리사이징(재해시) 비용과 table 재할당을 줄일 수 있다.
int capacity = (int) (n / 0.75f) + 1;
Map<Integer, Integer> m = new HashMap<>(capacity);
for (int i = 0; i < n; i++) m.put(i, i);
System.out.println("size=" + m.size());
}
}
실무 포인트: HashMap은 편의가 아니라 table + node 그래프를 만든다. lookup이 드물거나 중복이 거의 없다면, 비용 대비 효과가 떨어질 수 있다.
4) Object Layout: 객체 하나가 왜 비싼지 ‘측정’하기
설명만 들으면 헤더/패딩 때문에 비싸다가 감으로 남는다. 가장 확실한 방법은 JOL(Java Object Layout) 로 실제 크기를 찍는 것이다.
4-1. JOL 준비
Gradle:
1
2
3
dependencies {
implementation("org.openjdk.jol:jol-core:0.17")
}
Maven:
1
2
3
4
5
<dependency>
<groupId>org.openjdk.jol</groupId>
<artifactId>jol-core</artifactId>
<version>0.17</version>
</dependency>
4-2. boolean 하나 vs Boolean 하나
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
import org.openjdk.jol.info.ClassLayout;
public class LayoutDemo {
static class A { boolean flag; }
static class B { Boolean flag; }
public static void main(String[] args) {
System.out.println(ClassLayout.parseClass(A.class).toPrintable());
System.out.println(ClassLayout.parseClass(B.class).toPrintable());
// 실제 인스턴스도 확인 가능
System.out.println(ClassLayout.parseInstance(new A()).toPrintable());
System.out.println(ClassLayout.parseInstance(new B()).toPrintable());
}
}
여기서 확인해야 할 관찰 포인트는 두 가지다.
첫째, A는 boolean 하나인데도 정렬 때문에 객체 크기가 8바이트 단위로 맞춰진다.
둘째, B는 Boolean 객체를 추가로 만들 수 있고(캐시 사용 여부/상황에 따라), 참조 추적 비용까지 늘어난다.
4-3. 배열은 객체다: int 하나 담는데 왜 이렇게 커?
1
2
3
4
5
6
7
8
9
10
11
12
import org.openjdk.jol.info.GraphLayout;
public class ArrayLayoutDemo {
public static void main(String[] args) {
int[] a = new int[1];
Integer[] b = new Integer[1];
b[0] = 1;
System.out.println(GraphLayout.parseInstance(a).toFootprint());
System.out.println(GraphLayout.parseInstance(b).toFootprint());
}
}
primitive 배열은 연속 값이라 추적할 엣지가 거의 없지만, reference 배열은 배열 + 참조 + 박싱 객체로 그래프가 커진다.
5) GC 로그로 관찰하기: 진짜로 뭐가 살아 있나를 확인하는 방법
데모 코드는 관찰이 어려울 수 있다. 그럴 때는 GC 로그를 켜면 된다.
JDK 17 기준(예시):
1
java -Xms512m -Xmx512m -Xlog:gc*,safepoint:file=gc.log:time,uptime,level,tags -XX:+UseG1GC YourMain
메모리가 계속 안 줄어드는 상황이라면 GC가 못 치우는 게 아니라 Root 경로가 남아 있는지부터 의심해야 한다. 힙덤프/분석 도구(MAT, VisualVM, JFR)에서도 결국 핵심 질문은 동일하다.
이 객체까지의 Root path가 뭐냐?
마무리
Heap은 저장소가 아니라 그래프다. reference는 주소가 아니라 비용이고, 컬렉션은 그래프를 폭발시키는 허브다. Object Layout은 노드 하나하나의 단가를 끌어올린다.
이 셋이 결합되면 실무에서 보는 대부분의 힙 문제는 GC가 이상해서가 아니라 내가 만든 그래프가 그렇게 생겨서 발생한다.
다음 글에서는 Heap과 Stack이 만나는 경계(특히 write barrier, card table, young/old 승격)까지 이어서 GC를 더 깊게 풀어볼 수 있다.