Java 가비지 컬렉션 (Garbage Collection) 완벽 가이드
가비지 컬렉션이란 무엇인가
Java를 처음 배울 때 가장 인상적이었던 부분 중 하나는 메모리 관리를 개발자가 직접 하지 않아도 된다는 점이었다. C나 C++에서는 malloc()으로 메모리를 할당하고 free()로 해제하거나, new로 객체를 생성하고 delete로 소멸시키는 작업을 개발자가 명시적으로 수행해야 했다. 만약 이 과정에서 실수가 발생하면 메모리 누수(memory leak)나 이중 해제(double free), 댕글링 포인터(dangling pointer) 같은 심각한 버그가 발생할 수 있었다. Java는 이러한 문제를 근본적으로 해결하기 위해 가비지 컬렉션이라는 자동 메모리 관리 메커니즘을 도입했다.
가비지 컬렉션(Garbage Collection, GC)은 JVM의 Heap 영역에서 더 이상 사용되지 않는 객체, 즉 “가비지(Garbage)”를 자동으로 탐지하고 메모리에서 해제하는 기법이다. 여기서 “더 이상 사용되지 않는다”는 것은 프로그램의 어떤 부분에서도 해당 객체에 접근할 수 없다는 것을 의미한다. 예를 들어, 어떤 객체를 참조하던 변수가 다른 객체를 가리키게 되거나 null이 할당되면, 기존에 참조하던 객체는 더 이상 접근할 수 없게 되어 가비지가 된다.
1
2
3
4
5
6
7
8
9
10
11
12
13
public class GarbageExample {
public static void main(String[] args) {
// 새로운 Person 객체를 생성하고 person 변수가 참조
Person person = new Person("김철수");
// person 변수가 새로운 객체를 참조하게 됨
// 기존 "김철수" 객체는 더 이상 참조되지 않음 - Garbage!
person = new Person("이영희");
// "김철수" 객체는 이 시점부터 GC의 대상이 됨
// 언제 실제로 메모리에서 해제될지는 GC가 결정
}
}
이 코드에서 처음 생성된 “김철수” Person 객체는 두 번째 줄에서 person 변수가 새로운 객체를 가리키게 되면서 더 이상 프로그램에서 접근할 방법이 없어진다. 이렇게 고아가 된 객체는 GC의 수집 대상이 되고, GC가 실행될 때 메모리에서 제거된다.
“GC 대상”은 곧 “도달 불가능(Unreachable)”이다
많이들 “참조가 없으면 GC 대상”이라고 말하지만, 더 정확한 표현은 GC Root로부터 도달 가능하냐이다.
- 도달 가능(Reachable): GC Root에서 시작해 참조를 따라가면 닿는 객체 → 살아있음
- 도달 불가능(Unreachable): 어떤 경로로도 닿지 않는 객체 → GC 대상
즉, “변수 하나가 null이 됐다”가 핵심이 아니라, GC Root와의 연결이 끊겼다가 핵심이다.
Stop-The-World: GC의 대가
GC가 아무리 편리하다고 해도 공짜는 아니다. GC가 실행되는 동안에는 JVM이 애플리케이션의 실행을 일시적으로 멈춰야 하는데, 이를 “Stop-The-World(STW)”라고 부른다. 왜 이런 일이 필요할까? GC가 살아있는 객체를 판별하기 위해서는 객체들 사이의 참조 관계를 추적해야 하는데, 만약 이 작업 중에 애플리케이션이 계속 실행되면서 참조 관계를 변경한다면 정확한 판단이 불가능해지기 때문이다. 마치 움직이는 버스 안에서 승객 수를 세는 것과 같다고 생각하면 된다.
STW가 발생하면 GC를 수행하는 스레드를 제외한 모든 애플리케이션 스레드가 작업을 멈춘다. 이 시간 동안 애플리케이션은 사용자 요청에 응답하지 못하고, 시스템이 “멈춘” 것처럼 보인다. 따라서 GC 튜닝의 핵심 목표는 이 STW 시간을 최소화하는 것이다. 특히 실시간 응답이 중요한 시스템에서는 STW 시간이 서비스 품질에 직접적인 영향을 미치기 때문에 GC 선택과 튜닝이 매우 중요하다.
STW는 “없애는 것”이 아니라 “줄이고 예측하는 것”이다
ZGC, Shenandoah 같은 최신 저지연 GC도 STW를 0으로 만들지는 못한다. 대신 다음을 목표로 한다.
- STW가 필요한 구간을 최소화
- STW 시간을 짧게 유지 (예: 10ms 이하)
- STW가 언제 얼마나 발생할지 예측 가능하게 설계
실무에서 중요한 건 “GC가 있냐 없냐”가 아니라 P99/P999 latency에 STW가 어떤 영향을 주는지다.
Heap 메모리 구조의 이해
GC를 제대로 이해하려면 먼저 JVM Heap 메모리의 구조를 알아야 한다. JVM의 Heap은 크게 Young Generation과 Old Generation으로 나뉘며, 이러한 세대별 구분은 “대부분의 객체는 금방 소멸한다”는 경험적 관찰(Weak Generational Hypothesis)에 기반한다.
- JVM Heap Memory 구조
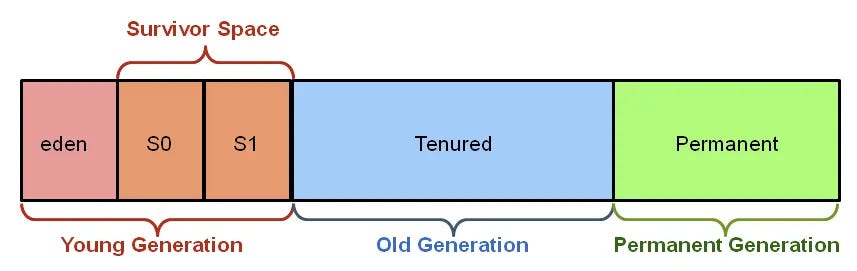
Young Generation은 새로 생성된 객체들이 배치되는 영역이다. 이 영역은 다시 Eden 영역과 두 개의 Survivor 영역(S0, S1 또는 From, To)으로 나뉜다. 새로운 객체는 항상 Eden 영역에 먼저 할당된다. Eden 영역이 가득 차면 Minor GC가 발생하고, 살아남은 객체들은 Survivor 영역 중 하나로 이동한다. Survivor 영역 사이에서 여러 번의 GC를 거치면서 살아남은 객체들은 결국 Old Generation으로 승격(Promotion)된다.
Old Generation은 Young Generation에서 오랫동안 살아남은 객체들이 저장되는 영역이다. 이 영역의 객체들은 상대적으로 수명이 길 것으로 예상되므로 GC가 덜 자주 발생하지만, 한 번 발생하면 처리해야 할 객체의 양이 많아 시간이 오래 걸린다. Old Generation에서 발생하는 GC를 Major GC 또는 Full GC라고 부른다.
Minor/Major/Full GC 용어는 “Collector마다 의미가 다를 수 있다”
전통적 용어로는 아래처럼 이해하는 게 맞지만,
- Minor GC: Young 대상 수집
- Major GC: Old 대상 수집
- Full GC: 전체 힙 + 추가 정리(클래스 언로딩 등)가 포함될 수 있음
G1/ZGC 같은 최신 GC에서는 “Young GC / Mixed GC / Full GC”처럼 조금 다른 용어를 쓰기도 한다.
따라서 로그나 튜닝을 볼 때는 용어 자체보다 “어떤 영역을 어떤 방식으로 수집했는지” 를 보는 게 정확하다.
객체의 생존 여정
객체가 생성되어 소멸하기까지의 과정을 단계별로 살펴보자. 이 과정을 이해하면 GC의 동작 원리를 더 명확하게 파악할 수 있다.
첫째, 새로운 객체가 생성되면 Eden 영역에 할당된다. 대부분의 객체는 생성된 직후 짧은 시간 안에 더 이상 필요 없어지는데, 이런 객체들은 다음 번 Minor GC에서 바로 제거된다.
둘째, Eden 영역이 가득 차면 Minor GC가 발생한다. 이때 GC는 Eden 영역과 현재 사용 중인 Survivor 영역(From)을 검사하여 살아있는 객체를 식별한다. 살아있는 객체들은 비어있는 Survivor 영역(To)으로 복사되고, 각 객체의 age(나이)가 1 증가한다.
셋째, Minor GC가 반복될 때마다 살아남은 객체들은 두 Survivor 영역 사이를 번갈아가며 이동한다. 이 과정에서 age가 계속 증가하며, 기본적으로 age가 15에 도달하면 Old Generation으로 승격된다. 이 임계값은 -XX:MaxTenuringThreshold 옵션으로 조정할 수 있다.
1
2
3
// 객체가 Old Generation으로 승격되는 age 임계값 설정
// 기본값은 15이며, G1 GC에서는 동적으로 조정됨
-XX:MaxTenuringThreshold=15
넷째, Old Generation이 가득 차면 Major GC가 발생한다. Major GC는 Old Generation 전체를 대상으로 하기 때문에 Minor GC보다 훨씬 오래 걸리고, 그만큼 STW 시간도 길어진다.
Promotion Failure / Allocation Failure가 성능을 무너뜨린다
실무에서 “GC가 느려진다”의 대표 원인은 Old가 단순히 찼기 때문이 아니라, 아래 상황이 겹쳤을 때다.
- Young에서 살아남은 객체를 Old로 올려야 하는데 Old에 연속 공간이 부족
- Eden에 새 객체를 넣어야 하는데 공간이 부족
- 결과적으로 “예상보다 더 큰” 정리 작업(Full GC)을 호출
즉, 단순히 “Old가 가득 참 → Major GC”가 아니라, 승격/할당 실패가 연쇄적으로 STW를 키우는 시나리오가 많다.
GC 알고리즘의 발전
Reference Counting의 한계
초기의 메모리 관리 기법 중 하나인 Reference Counting은 각 객체가 참조되는 횟수를 카운트하여 0이 되면 해제하는 방식이다. 직관적이고 구현이 간단하지만, 치명적인 문제가 있다. 바로 순환 참조(circular reference)를 처리할 수 없다는 것이다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
class Node {
Node next;
String data;
Node(String data) {
this.data = data;
}
}
// 순환 참조 문제 예시
Node nodeA = new Node("A");
Node nodeB = new Node("B");
nodeA.next = nodeB; // A가 B를 참조
nodeB.next = nodeA; // B가 A를 참조
nodeA = null; // 변수 참조 해제
nodeB = null; // 변수 참조 해제
// 이 시점에서 두 Node 객체는 서로를 참조하고 있어
// Reference Count가 0이 되지 않음 -> 메모리 누수 발생!
이 문제를 해결하기 위해 현대의 JVM은 Reference Counting 대신 도달 가능성(Reachability) 기반의 알고리즘을 사용한다.
Mark and Sweep: 현대 GC의 기반
Mark and Sweep은 현대 JVM GC의 기본이 되는 알고리즘이다. 이 알고리즘은 두 단계로 동작한다. 먼저 Mark 단계에서 GC Root로부터 시작하여 참조 체인을 따라 도달 가능한 모든 객체에 마크를 한다. 그 다음 Sweep 단계에서 마크되지 않은 모든 객체를 메모리에서 제거한다.
GC Root가 될 수 있는 것들은 다음과 같다. 첫째, JVM 스택의 지역 변수와 파라미터 참조. 둘째, Method Area의 static 변수. 셋째, JNI(Java Native Interface)에 의해 생성된 객체. 넷째, 실행 중인 스레드 자체. 이러한 GC Root에서 시작하여 참조를 따라가며 도달할 수 있는 모든 객체는 “살아있는” 것으로 판정된다.
GC Root는 “누수 원인”을 찾는 지도다
실무에서 메모리 누수의 대부분은 아래 패턴으로 설명된다.
- GC Root(스택/스레드/static/JNI) 중 하나가 참조를 계속 붙잡고 있음
- 그래서 “쓰레기처럼 보이는 객체”도 Reachable로 남아 회수되지 않음
대표 사례:
- static Map/List에 계속 쌓이는 캐시
- ThreadLocal에 넣고 remove()를 안 한 경우
- 등록한 Listener/Callback을 해제하지 않은 경우
Mark-Sweep-Compact: 단편화 해결
순수한 Mark and Sweep 알고리즘에는 메모리 단편화(fragmentation) 문제가 있다. 객체들이 제거된 후 메모리에 불연속적인 빈 공간들이 생기면, 큰 객체를 할당해야 할 때 연속된 공간을 찾기 어려워진다. Mark-Sweep-Compact 알고리즘은 Sweep 이후에 Compaction 단계를 추가하여 살아남은 객체들을 메모리의 한쪽으로 모아 정리한다.
1
2
3
4
5
6
7
8
9
Compact 전:
┌───┬───┬───┬───┬───┬───┬───┬───┐
│ A │ │ B │ │ │ C │ │ D │ (빈 공간이 흩어져 있음)
└───┴───┴───┴───┴───┴───┴───┴───┘
Compact 후:
┌───┬───┬───┬───┬───┬───┬───┬───┐
│ A │ B │ C │ D │ │ │ │ │ (연속된 빈 공간 확보)
└───┴───┴───┴───┴───┴───┴───┴───┘
Compaction은 단편화 문제를 해결하지만, 객체들의 위치가 변경되므로 해당 객체를 참조하는 모든 포인터도 갱신해야 한다. 이 추가 작업으로 인해 오버헤드가 발생하며, GC 시간이 늘어나는 트레이드오프가 있다.
Compaction은 “STW를 줄이는 도구”이기도 하다
단편화가 심해지면 큰 객체 할당이 실패하고 승격(Promotion)도 실패하며 결국 더 큰 GC(Full GC)가 유발된다. 따라서 “컴팩션은 오버헤드”이기도 하지만, 장기적으로는 더 큰 STW를 예방하는 역할도 한다.
다양한 GC 구현체들

초기에는 Serial GC와 Parallel GC가 사용되었지만, 애플리케이션의 규모와 성능 요구사항이 증가함에 따라 CMS (Concurrent Mark Sweep), G1 GC (Garbage First), ZGC (Z Garbage Collector) 등이 도입되다.
1. Serial GC: 단순함의 미덕
Serial GC는 가장 단순한 형태의 가비지 컬렉터다. 이름에서 알 수 있듯이 단일 스레드로 GC를 수행하며, GC 동안에는 모든 애플리케이션 스레드가 멈춘다. 메모리와 CPU 코어가 적은 환경에서 효율적이며, 클라이언트 타입의 JVM에서 기본 GC로 사용된다. -XX:+UseSerialGC 옵션으로 활성화할 수 있다.
2. Parallel GC: 처리량 극대화
Parallel GC(또는 Throughput Collector)는 Serial GC의 멀티스레드 버전이다. 여러 스레드가 동시에 GC 작업을 수행하므로 Serial GC보다 빠르게 완료된다. Java 8까지의 기본 GC였으며, 처리량(throughput)을 최대화하는 것이 목표다. 배치 작업이나 대량 데이터 처리처럼 응답 시간보다 전체 처리량이 중요한 환경에 적합하다.
1
2
3
4
5
# Parallel GC 활성화
-XX:+UseParallelGC
# GC에 사용할 스레드 수 지정
-XX:ParallelGCThreads=4
Throughput GC에서 “좋은 성능”의 기준
Parallel GC는 응답시간(Pause)보다 처리량이 목표다. 그래서 실무에서는 아래 지표로 판단하는 편이 좋다.
- GC로 소비된 시간 비율이 낮은가? (GC overhead)
- Full GC 빈도가 낮은가?
- TPS/배치 처리량이 목표치에 도달하는가?
3. CMS GC: 응답 시간 중시
CMS(Concurrent Mark Sweep) GC는 STW 시간을 최소화하기 위해 설계되었다. 애플리케이션 스레드와 GC 스레드가 동시에 실행되는 Concurrent 방식을 도입했다. Initial Mark와 Remark 단계에서만 짧은 STW가 발생하고, 대부분의 작업(Concurrent Mark, Concurrent Sweep)은 애플리케이션과 병행하여 진행된다.
하지만 CMS GC에는 몇 가지 단점이 있었다. Compaction을 수행하지 않아 메모리 단편화가 발생할 수 있고, Concurrent 작업 중에 Old Generation이 가득 차면 “Concurrent Mode Failure”가 발생하여 Full GC로 fallback된다. 이러한 문제들로 인해 CMS GC는 Java 9에서 deprecated되었고 Java 14에서 완전히 제거되었다.
CMS의 핵심 트레이드오프: “짧은 STW”를 위해 “여유 공간”을 희생한다
CMS는 애플리케이션과 동시에(Concurrent) 마킹/스윕을 한다. 그런데 애플리케이션이 실행되는 동안에도 객체 할당은 계속된다.
즉, CMS는 다음 상황에 매우 취약하다.
- Old Gen에 여유가 부족한 상태에서
- 애플리케이션이 높은 할당률(Allocation Rate)을 보이면
- Concurrent Mark/Sweep가 끝나기 전에 Old가 먼저 차버릴 수 있다.
이게 바로 CMS의 대표 실패 시나리오다.
Concurrent Mode Failure가 왜 위험한가?
CMS가 “동시에 처리”하려고 했던 이유는 긴 STW(Full GC)를 피하기 위해서였다.
하지만 Concurrent Mode Failure가 발생하면 결국 Full GC(대개 Mark-Compact) 로 강제 fallback 된다.
- STW가 갑자기 길어짐 (예측 불가)
- 지연 시간이 튀면서 서비스 품질에 직접 영향
- 단편화 문제까지 누적되어 반복적으로 Full GC가 유발될 수 있음
그래서 CMS는 “낮은 지연”을 목표로 했지만 운영 안정성 측면에서 예측이 어려운 GC로 평가되었다.
CMS 단편화(Fragmentation)가 “진짜 문제”가 되는 순간
CMS는 기본적으로 Compaction을 하지 않으므로, 메모리 공간이 조각조각 흩어질 수 있다.
이때 자주 발생하는 운영 이슈는:
- Old에 전체 여유 메모리는 충분한데
- “연속된 큰 공간”이 부족해서
- 큰 객체 할당이나 Promotion이 실패하는 상황
즉 “남아있는 빈칸은 많은데, 쓸 수 있는 자리(연속 공간)는 없는” 상태가 된다.
4. G1 GC: 새로운 기본 GC
G1(Garbage First) GC는 Java 9부터 기본 GC가 되었으며, 대용량 Heap에서 안정적인 성능을 제공하도록 설계되었다. G1 GC의 가장 큰 특징은 Heap을 고정된 크기의 Region으로 분할한다는 것이다. 각 Region은 Eden, Survivor, Old 중 하나의 역할을 동적으로 담당하며, 큰 객체는 여러 Region에 걸쳐 저장되는 Humongous Region이 된다.
1
2
3
4
5
6
7
8
9
10
G1 GC의 Region 기반 Heap 구조:
┌───┬───┬───┬───┬───┬───┬───┬───┐
│ E │ E │ S │ O │ O │ E │ H │ O │
├───┼───┼───┼───┼───┼───┼───┼───┤
│ O │ E │ E │ │ S │ O │ O │ E │
├───┼───┼───┼───┼───┼───┼───┼───┤
│ │ O │ O │ E │ E │ │ O │ S │
└───┴───┴───┴───┴───┴───┴───┴───┘
E: Eden, S: Survivor, O: Old, H: Humongous, 빈칸: Free
G1 GC는 “Garbage First”라는 이름처럼 가비지가 가장 많은 Region을 우선적으로 수집한다. 또한 목표 Pause Time을 설정할 수 있어서(-XX:MaxGCPauseMillis), GC가 해당 시간 내에 완료될 수 있도록 수집할 Region의 양을 조절한다. 이러한 예측 가능한 STW 시간이 G1 GC의 큰 장점이다.
G1을 “진짜로 이해하는” 핵심 키워드 4개
G1은 단순히 “Region으로 나눴다”가 핵심이 아니라, 어떻게 Old를 예측 가능한 방식으로 수집하느냐가 핵심이다.
G1을 이해할 때 반드시 알아야 하는 키워드 4개는 다음이다.
1) Region
2) Remembered Set(RSet)
3) SATB(Snapshot-At-The-Beginning)
4) Mixed GC
1) Region: Eden/Survivor/Old가 고정이 아니다
기존 GC는 Young/Old가 물리적으로 분리돼 있고, 영역의 의미가 비교적 고정되어 있다.
G1은 Heap을 동일 크기의 Region으로 쪼개고, 각 Region이 상황에 따라 Eden/Survivor/Old 역할을 바꾼다.
즉, G1의 Young/Old는 “고정된 공간”이 아니라 “역할(role)” 개념이다.
2) Remembered Set(RSet): Old 수집을 가능하게 만드는 장치
Young GC에서 살아있는 객체를 판단하려면, Young 안의 객체가 어디서 참조되는지를 알아야 한다.
문제는 Old → Young 참조가 있을 수 있다는 점이다. 이걸 매번 Old 전체를 훑어서 찾으면 Young GC가 “빠른 수집”이 아니게 된다.
그래서 G1은 Region 단위로 “외부 Region이 이 Region을 참조하는 정보”를 RSet으로 관리한다.
- Young GC 시: Old 전체 스캔 ❌
- Young이 참조된 경로만 RSet 기반으로 확인 ✅
대신 비용이 있다. 참조가 업데이트될 때마다 RSet 유지 비용(쓰기 장벽, write barrier) 이 발생한다.
3) SATB: Concurrent Marking을 가능하게 하는 논리
G1은 Old 수집을 위해 Concurrent Marking을 수행한다. 그런데 애플리케이션이 동시에 실행되면 참조 그래프가 바뀐다.
SATB(Snapshot-At-The-Beginning)는 “마킹을 시작한 시점의 스냅샷 기준으로 생존 객체를 판단”하는 전략이다.
핵심은 다음이다.
- 마킹 시작 시점에 살아있던 객체는 놓치면 안 된다.
- 그래서 참조가 끊기는 순간(삭제되는 순간) 그 객체를 별도로 기록한다.
이때 사용되는 개념이 write barrier(정확히는 pre-write barrier)다.
SATB는 “GC 도중 참조가 바뀌어도”
마킹 누락을 막기 위한 장치다.
4) Mixed GC: G1이 “Garbage First”가 되는 지점
G1의 Old 수집은 대개 다음 순서로 진행된다.
1) Young GC (Young만 수집) 2) Concurrent Marking (Old의 live 데이터 비율을 Region별로 파악) 3) Mixed GC (Young + Old 일부 Region을 함께 수집)
Mixed GC가 중요한 이유:
- Old 전체를 한 번에 다 치우는 Full GC를 피하고
- “가비지가 많은 Old Region”부터 조금씩 치운다
- 그래서 STW를 짧고 예측 가능하게 유지한다
즉, G1의 강점은 “Region” 자체가 아니라 Mixed GC로 Old를 쪼개 수집한다는 점에 있다.
Humongous Object: G1에서 자주 터지는 함정
원문에서도 Humongous를 언급했는데, 실무에서는 이게 성능/안정성에 진짜로 큰 영향을 준다.
Humongous 객체는 보통 다음 조건을 만족할 때로 설명된다.
- 객체 크기가 Region 크기의 일정 비율 이상(대개 매우 큼)
- 한 Region에 못 들어가면 여러 Region을 연속으로 차지
문제는 다음이다.
- 큰 객체는 Young에서 빨리 죽는다는 가정과 다르게 “Old처럼” 취급되기 쉽다
- 연속 Region을 많이 잡아먹어서 단편화/여유 공간을 악화시킨다
- Mixed GC가 처리할 후보 Region 선택에도 영향을 준다
실무 팁:
- 갑자기 GC가 불안정해졌는데 대형 배열/버퍼가 늘었다면
“Humongous Allocation”을 먼저 의심한다.
G1 GC 튜닝 옵션을 “의미”로 연결하기
원문에 이미 옵션이 있지만, 실무에서는 “값”보다 “의미”가 중요하다.
-XX:MaxGCPauseMillis=200- “200ms 안에 끝내”가 아니라,
- 200ms 목표에 맞춰 수집량(Region 수)을 조절한다는 의미
- 목표를 너무 낮추면 GC가 자주 발생할 수 있음(오버헤드 증가)
-XX:G1HeapRegionSize=4m- Region 크기가 작으면: RSet 등 메타데이터 비용 증가
- Region 크기가 크면: 세밀한 수집이 어려워져 Pause 예측성이 떨어질 수 있음
결국 튜닝은 “좋은 숫자 찾기”가 아니라 우리 서비스 패턴(할당률, 객체 수명, 트래픽 변동) 에 맞추는 작업이다.
5. ZGC와 Shenandoah: 초저지연의 시대
최신 JVM에서는 STW 시간을 극단적으로 줄인 초저지연 GC가 등장했다. ZGC는 Oracle에서 개발했으며, 수 테라바이트 규모의 Heap에서도 10ms 이하의 STW 시간을 목표로 한다. Java 15부터 Production Ready 상태가 되었다.
ZGC는 Colored Pointers와 Load Barriers라는 기술을 사용한다. 포인터의 일부 비트를 GC 메타데이터로 활용하여, 객체가 이동되더라도 참조를 갱신하는 작업을 점진적으로 수행할 수 있다. 이를 통해 대부분의 GC 작업을 애플리케이션과 동시에 수행하면서도 일관된 저지연 성능을 제공한다.
Shenandoah GC는 Red Hat에서 개발한 저지연 GC로, ZGC와 비슷한 목표를 가지고 있다. OpenJDK에 포함되어 있으며, Concurrent Compaction을 지원한다.
1
2
3
4
5
# ZGC 활성화 (Java 15+)
-XX:+UseZGC
# Shenandoah GC 활성화 (OpenJDK)
-XX:+UseShenandoahGC
저지연 GC의 공통점: “동시(compaction) + 장벽(barrier) + 포인터 트릭”
ZGC/Shenandoah는 접근 방식은 다르지만 공통된 결을 가진다.
- 애플리케이션 스레드와 동시에 대부분의 단계 수행
- 객체 이동(Compaction)을 동시로 수행
- 이를 위해 read/write barrier로 접근 시점을 가로챔
- 포인터/메타데이터를 활용해 “점진적 참조 갱신”을 수행
즉, STW를 줄이는 대가는 다음이다.
- 장벽(Barrier)로 인한 애플리케이션 실행 경로 오버헤드
- 구현 복잡도 증가
- 튜닝/관찰 포인트가 달라짐
그래서 “무조건 ZGC가 최고”가 아니라, “우리 서비스의 지연 요구사항이 정말 그런가?”를 먼저 따져야 한다.
ZGC 내부 동작을 감으로 이해하기
ZGC는 “STW를 없앴다”가 아니라
STW가 필요한 순간을 극단적으로 줄였다는 데 의미가 있다.
이를 가능하게 만든 핵심은 다음 두 가지다.
- Colored Pointer
- Load Barrier
Colored Pointer: 포인터에 메타데이터를 담는다
ZGC는 객체 포인터의 일부 비트를 GC 상태 정보로 사용한다. (예: Marked, Relocated, Remapped 등)
즉, 객체의 상태를 별도의 테이블이 아니라 포인터 자체에 인라인으로 표현한다.
이로 인해 얻는 장점은:
- 객체 이동 여부를 즉시 판단 가능
- 참조 갱신을 “나중에” 또는 “필요할 때” 수행 가능
- STW 구간에서 모든 참조를 한 번에 고칠 필요가 없음
Load Barrier: “접근 시점”에 정합성을 보장한다
ZGC에서는 객체를 참조하려는 순간, Load Barrier가 개입한다.
1
2
3
4
5
객체 접근 →
Load Barrier 실행 →
이 객체가 이동됐는가?
YES → 최신 위치로 참조 갱신
NO → 그대로 사용
즉, ZGC는
- “모든 참조를 미리 고친다” ❌
- “접근할 때마다 필요한 만큼만 고친다” ✅
이 방식 덕분에 대규모 힙에서도 객체 이동(Compaction)을 Concurrent로 수행할 수 있다.
ZGC의 핵심 트레이드오프
ZGC는 STW를 줄이는 대신 다음 비용을 지불한다.
- 모든 객체 접근 경로에 Barrier 존재
- 포인터 처리 비용 증가
- 단순한 배치 처리에서는 오히려 불리할 수 있음
그래서 ZGC는 다음 상황에서 빛난다.
- P99/P999 latency가 중요한 서비스
- 대용량 Heap (수십 GB ~ TB)
- 긴 Full GC가 절대 허용되지 않는 환경
GC 선택과 튜닝
어떤 GC를 선택해야 할지는 애플리케이션의 특성에 따라 다르다. 처리량이 중요하고 가끔 긴 Pause가 허용된다면 Parallel GC가 좋다. 일반적인 서버 애플리케이션에서 균형 잡힌 성능을 원한다면 G1 GC가 적합하다. 실시간 응답이 매우 중요한 시스템이라면 ZGC나 Shenandoah를 고려해볼 만하다.
GC 튜닝의 기본은 적절한 Heap 크기를 설정하는 것이다. Heap이 너무 작으면 GC가 너무 자주 발생하고, 너무 크면 한 번의 GC에 시간이 오래 걸린다. 일반적으로 초기 Heap 크기(-Xms)와 최대 Heap 크기(-Xmx)를 같게 설정하여 Heap 크기 조정으로 인한 오버헤드를 줄이는 것이 권장된다.
1
2
3
4
5
6
7
8
# 기본적인 Heap 설정
-Xms4g -Xmx4g
# G1 GC 목표 Pause Time 설정 (밀리초)
-XX:MaxGCPauseMillis=200
# GC 로그 활성화 (Java 9+)
-Xlog:gc*:file=gc.log:time,level,tags
메모리 누수 방지하기
GC가 있다고 해서 메모리 누수가 절대 발생하지 않는 것은 아니다. 의도치 않게 객체에 대한 참조를 계속 유지하면 GC가 해당 객체를 회수하지 못한다. 특히 static 컬렉션에 객체를 추가만 하고 제거하지 않거나, 리스너를 등록한 후 해제하지 않는 경우가 흔한 메모리 누수 원인이다.
WeakReference나 SoftReference를 활용하면 캐시처럼 메모리가 부족할 때 해제되어도 괜찮은 객체들을 관리할 수 있다. 또한 try-with-resources 구문을 사용하여 리소스가 확실히 해제되도록 하는 것이 좋다.
1
2
3
4
5
6
7
8
9
// WeakReference를 활용한 캐시 구현
Map<String, WeakReference<ExpensiveObject>> cache = new HashMap<>();
// try-with-resources로 리소스 자동 해제
try (Connection conn = dataSource.getConnection();
PreparedStatement ps = conn.prepareStatement(sql);
ResultSet rs = ps.executeQuery()) {
// 사용 후 자동으로 close() 호출됨
}
면접 대비 핵심 정리
GC 관련 면접 질문에서 자주 나오는 주제들을 정리하면 다음과 같다. Minor GC와 Major GC의 차이는 대상 영역의 차이다. Minor GC는 Young Generation을 대상으로 자주, 빠르게 실행되고, Major GC는 Old Generation을 대상으로 드물게, 느리게 실행된다.
Java 버전별 기본 GC는 Java 8까지 Parallel GC, Java 9 이후로는 G1 GC다. STW가 발생하는 이유는 정확한 참조 추적을 위해 객체 참조 관계가 변경되지 않도록 애플리케이션을 일시 정지해야 하기 때문이다.
메모리 누수 방지를 위해서는 사용하지 않는 객체 참조를 명시적으로 해제하고, static 컬렉션 사용에 주의하며, 리소스는 반드시 close하고, 필요한 경우 WeakReference를 활용해야 한다.
GC를 깊이 이해하면 메모리 관련 성능 문제를 진단하고 해결하는 능력이 향상된다. 단순히 GC의 종류를 아는 것을 넘어서, 각 GC가 왜 그렇게 설계되었는지, 어떤 상황에서 어떤 GC가 적합한지를 이해하는 것이 중요하다.